

はじめに
現在自分で作成しているシステムでS3にファイルをアップロードしたら、LambdaとTranslateを使用して自動翻訳してくれるシステムを構築していた際の話になります。今回はほとんどAmazon Q Developerに作業をしてもらい構築していたのですが、生成AIの扱いに慣れておらず失敗した話になります。
作ろうとしたシステム
作ろうとしたシステムはS3のイベント通知を使って、翻訳したファイルを生成するという簡単なものになっております。このシステム構築を通して、得た気づきが二点あります。
- 入力: S3バケットにtxt/docxファイルをアップロード
- 処理: Lambda関数が自動実行してTranslateで翻訳
-
出力: 翻訳結果を同じバケットの
translated/フォルダに保存
第一の気づき:最低限具体的にプロンプトを投げる
一つ目はあまりに私が素人すぎたのがいけないのですが、あまりにも適当にプロンプトを投げすぎてしまい、以下のような問題点が出ました。
- Wordファイルがtxtファイルで出力される
- Translateでバッチ処理で処理しようとする
Translateのサービスはリアルタイム処理とバッチ処理の二つの処理があります。初めに使用した際は、WordファイルをTXTに変換した後にTXT形式で出力するプログラムが生成されました。また、修正してと伝えた際は、Wordはリアルタイム処理で可能であるのですが、処理時間が遅れてしまうバッチ処理で行うプログラムが生成されました。
具体的な問題例
最初に生成されたコード(書式が失われる):
# Wordファイルからテキストを抽出してTXTで出力
def extract_text_from_docx(file_content):
doc = Document(io.BytesIO(file_content))
return '\n'.join([paragraph.text for paragraph in doc.paragraphs])
次に生成されたコード(バッチ処理で遅い):
# バッチ処理(数分~数十分かかる)
translate.start_text_translation_job(
JobName=f"translate-{name_without_ext}",
InputDataConfig={'S3Uri': f's3://{bucket}/{key}'},
OutputDataConfig={'S3Uri': 's3://output-bucket/'},
SourceLanguageCode='ja',
TargetLanguageCodes=['en']
)
正直適当にプロンプトを投げてもAmazon Q Developerで進めていると、AWSの環境もコマンドで構築してくれたり、勝手に構築してくれます。細かい部分は自分で修正する必要もあるかもしれないですが、自分の中で考えている最低限の仕様ぐらいはプロンプトに含めないといけないと思いました。
改善されたプロンプト例:
「WordファイルはWord形式のまま、リアルタイムで翻訳して出力してください」
第二の気づき:問題が発生しそうな部分は立ち止まって見直すべき
今回システムを構築している際に、タイトルにもあるようにS3のイベント通知で無限ループが発生しました。具体的にどういう問題が起きたかというと、S3がどこに置いてもイベント通知が発生する設定にしていたことと、Lambdaで作成したファイルを同じバケット内に配置することが原因で、何度もイベント通知が発生してファイルが何度も作成される事態に陥りました。
無限ループの仕組み
# 問題のあるコード
output_key = f"translated/{key.rsplit('.', 1)[0]}_en.txt"
s3.put_object(
Bucket=bucket, # 同じバケット!
Key=output_key,
Body=translated_text.encode('utf-8')
)
何が起きたか:
-
test.txtをアップロード - Lambda実行 →
translated/test_en.txt作成 translated/test_en.txtがS3イベントを再発火- Lambda実行 →
translated/translated/test_en_en.txt作成 - また発火…無限ループ開始 🔥
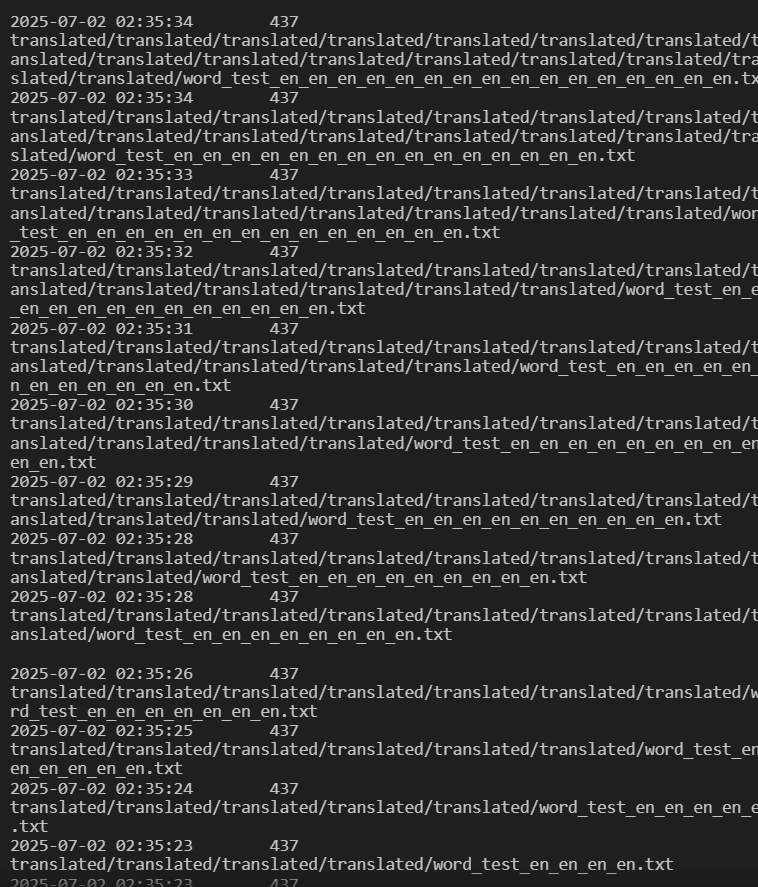
他でイベント通知を試して無限ループの可能性があることを知っていたにもかかわらずやってしまったことになります。Amazon Q Developerを使えばコマンドも自動で実行してくれますが、ファイルの操作がAIが定義した処理などで行われる際は、実行する前にあらかじめ起こりうる問題を想定することが大事だと思います。今回だとLambdaのコードを見たり、出力バケットを変えたりするだけで起こらなかったと思います。
解決策
# 修正後:別バケットに出力
s3.put_object(
Bucket='nextcloud-output-s3', # 別バケット
Key=output_key,
Body=translated_text.encode('utf-8')
)
最終的に完成したシステム
最終的には以下のような仕様で完成しました:
def lambda_handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = urllib.parse.unquote_plus(record['s3']['object']['key'])
if key.endswith('.txt'):
# テキスト翻訳
response = s3.get_object(Bucket=bucket, Key=key)
content = response['Body'].read().decode('utf-8')
translated_text = translate_text(content)
s3.put_object(
Bucket='output-s3', # 別バケット
Key=f"{name_without_ext}_en.txt",
Body=translated_text.encode('utf-8')
)
elif key.endswith('.docx'):
# ドキュメント翻訳(書式保持)
response = s3.get_object(Bucket=bucket, Key=key)
document_content = response['Body'].read()
translate_response = translate.translate_document(
Document={
'Content': document_content,
'ContentType': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document'
},
SourceLanguageCode='ja',
TargetLanguageCode='en'
)
s3.put_object(
Bucket='output-s3', # 別バケット
Key=f"{name_without_ext}_en.docx",
Body=translate_response['TranslatedDocument']['Content']
)
最終仕様:
- ✅ txtファイル: リアルタイム翻訳
- ✅ docxファイル: 書式保持したままリアルタイム翻訳
- ✅ 無限ループ解決: 出力先を別バケットに変更
まとめ
私みたいにAI初心者で同じようなことをしないように、何か参考になれば幸いです。
Amazon Q Developerは非常に強力なツールですが、使う側の指示の仕方や設計レビューが重要だということを学びました。AIに任せきりにするのではなく、適切なコミュニケーションと検証が必要ですね。
おまけ
ループは発生しましたが、LambdaやTranslateは無料枠で収まったみたいです。
- Lambda実行: 63回(無料枠: 100万回/月)
- Translate: 約3,000文字(無料枠: 200万文字/月)
- 請求額: $0

Views: 0

{kind=link}