
はじめに
近年、ChatGPTをはじめとする大規模言語モデル(LLM)の登場により、「自然言語処理(NLP)」技術の重要性も高まってきています。
私自身、検索エンジンを搭載したアプリケーション開発に携わる中で、その重要性を日々痛感しています。しかし、「形態素解析」や「ベクトル検索」といった各要素の役割や繋がりを明確に言語化できず、知識が断片的な状態でした。
この記事では、自然言語処理の分野で特に重要なキーワードを厳選し、
- そもそもどういう概念なのか? (What?)
- どのような意味合いで使われるのか? (Why/How?)
- エンジニアとして業務上どう活用するのか? (Use Case)
という3つの観点を元に各キーワードや概念を解説していきます。
本記事では、あくまで自身が担当する「特に検索応用分野」に焦点を当てて各要素を解説します。ざっくりとした全体像を掴むことを目的としていること、ご了承ください。
対象読者
- 自然言語処理や検索エンジンに伴う周辺知識の基本的な概念を学びたい方
- 「ベクトル検索」や「RAG」といった言葉になんとなく興味がある方
ステップ1: テキストの前処理(形態素解析, 正規化)
すべての基本であり、最も重要なのがこの「前処理」です。料理でいうところの食材の下ごしらえにあたります。生のテキストデータには、表記の揺れや不要な記号など、分析のノイズとなるものが多く含まれています。これらをきれいに整え、コンピュータが扱いやすい形にすることが目的です。
形態素解析
【概念(What?)】
日本語のように単語間にスペースがない言語を、意味を持つ最小単位(形態素)に分割する技術
【意味合い(Why/How?)】
コンピュータは文章を「単語の集まり」として処理します。「東京都でお寿司を食べる」という文も、形態素解析によって「東京/都/で/お/寿司/を/食べる」と分割されて初めて、コンピュータは各単語を認識し、検索や分析の対象にできます。分かち書きのない日本語には必須の処理です。
【エンジニアの活用シーン(Use Case)】
- 検索エンジンがWebページの内容をインデックス化(索引付け)する際の、最初の処理として利用する
- ユーザーが入力した問い合わせ文章を単語に区切り、キーワードを抽出する
- SNSの投稿を分析し、頻出する単語をランキング表示する際の基礎処理
正規化 (表記揺れ統一)
【概念(What?)】
全角・半角の統一、大文字・小文字の統一、旧字体を新字体に変換するなど、表記が異なるが意味は同じ単語を、特定のルールで統一する処理
【意味合い(Why/How?)】
「iPhone」と「iPhone」、「AI」と「ai」などをコンピュータは別物として扱ってしまいます。正規化を行うことで、これらの表記揺れを吸収し、検索漏れやデータの集計ミスを防ぎます。データ全体の品質を担保する重要な工程です。
【エンジニアの活用シーン(Use Case)】
- ユーザー登録フォームで入力された住所氏名の全角・半角を統一し、DBに保存する。
- ユーザーからの検索クエリを正規化し、検索対象のデータとマッチングしやすくする。
ステップ2:テキストのベクトル化 (n-gram, TF-IDF, エンベディング)
ステップ1で綺麗にしたテキストを、コンピュータが数学的に扱える数値の形式、すなわち「ベクトル」に変換するのがこのステップです。ベクトル化には、単語の出現頻度に着目する古典的なアプローチ(n-gram, TF-IDF)と、単語や文章の「意味」そのものを捉えようとする現代的なアプローチ(エンベディングモデル)が存在します。
n-gram
【概念(What?)】
テキストを、連続する「n」個の文字または単語で区切ってリスト化する手法
【意味合い(Why/How?)】
単語の並び順や、単語同士の繋がりを簡易的に捉えることができます。特に日本語では、形態素解析が難しい未知語や固有名詞でも、「文字n-gram」を使うことで部分一致検索が可能になり、検索漏れを防ぐ効果があります。
【エンジニアの活用シーン(Use Case)】
検索エンジンで、”東京スカイツリー”という単語を「東京」「京ス」「スカ」「カイ」「イツ」「ツリ」「リー」のように2文字(バイグラム)でインデックス化し、「スカイツリー」での検索に対応させる。
TF-IDF
【概念(What?)】
文書内での単語の出現頻度(TF)と、全文書における単語の希少性(IDF)を掛け合わせ、単語の「重要度」をスコア化する古典的な手法
【意味合い(Why/How?)】
「その文書を特徴づける単語とは、その文書内では頻出するが、他の文書ではあまり使われない単語である」という考えに基づいています。これにより、単なる出現回数よりも的確に、文書のトピックを表すキーワードを数値化できます。
【エンジニアの活用シーン(Use Case)】
- ニュース記事の内容を解析し、スコアの高い単語を自動的にタグとして付与する
- 古典的な検索システムで、検索クエリと文書の関連度を計算し、ランキングに利用する
エンベディングモデル (BERT, Googleのtext-embedding-004など)
【概念(What?)】
AIを用いて、単語や文章が持つ意味そのものを高次元のベクトルとして表現するモデルの総称。Googleのtext-embedding-004は、その中でも特に高性能な現代の代表的モデルである。膨大なテキストデータを学習して、言葉や文章の意味を数値の配列(ベクトル)に変換する能力を獲得した、巨大なニューラルネットワーク。
【意味合い(Why/How?)】
TF-IDFが単語の「重要度」しか見れないのに対し、エンベディングモデルは単語の「意味」を捉えます。これにより、「会社」と「企業」のように文字列は違えど意味が近い単語を、ベクトル空間上で「近い位置」に配置できます。コンピュータが言葉の意味を計算できるようになった、画期的な技術です。特にBERTやGPTは文脈も読めるため、多義語も正しく扱えます。
【エンジニアの活用シーン(Use Case)】
- ECサイトで「PC」と検索したユーザーに、意味的に近い「ノートパソコン」や「デスクトップ」も推薦する
- 記事の重複チェックで、言い回しが違っていても内容が似ている記事を検出する
- 後述の「ベクトル検索」や「RAG」を実現するための根幹技術として利用する
ステップ3:検索の手法(ベクトル検索, ハイブリッド検索, ANN)
数値化された膨大なデータの中から、必要な情報(ベクトル)を効率的に探し出すのがこのステップです。
ベクトル検索 (セマンティック検索)
【概念(What?)】
エンベディングされたベクトル空間上で、ユーザーの質問(クエリ)のベクトルと「意味が近い」ベクトルを持つデータを探し出す検索アプローチ。意味で探すことから「セマンティック検索」とも呼ばれる
【意味合い(Why/How?)】
従来のキーワード検索では、単語が完全に一致しないとヒットしませんでした。ベクトル検索は、意味の近さ(ベクトルの距離)で検索するため、「PC おすすめ 安い」といった曖昧なクエリに対しても、「コスパの良いラップトップ」という表現を含む文書を見つけ出すことができます。
【エンジニアの活用シーン(Use Case)】
- 社内規定に関するFAQチャットボットで、社員の様々な言い回しの質問に対して、意図を汲み取って最適な回答を提示する
- 類似画像検索システムで、アップロードされた画像と似た構図や雰囲気の画像を検索する
ハイブリッド検索
【概念(What?)】
キーワード検索とベクトル検索を組み合わせる手法
【意味合い(Why/How?)】
ベクトル検索は意図を汲めますが、特定の固有名詞や製品型番などには弱いことがあります。キーワード検索の確実性とベクトル検索の柔軟性を両立させる、実践的なアプローチです。
【エンジニアの活用シーン(Use Case)】
ECサイトの商品検索で、「MacBook Pro M3(キーワード検索で確実に絞り込み) 動画編集向け(ベクトル検索で関連レビューや特徴を考慮)」のように組み合わせる。
近似最近傍探索 (ANN)
【概念(What?)】
ベクトル検索を、現実的な速度で実行するための高速化アルゴリズムの総称
【意味合い(Why/How?)】
数百万、数億件のベクトル全てと距離を計算するのは非常に時間がかかります。ANNは、探索空間をあらかじめクラスタリングしておくなどの工夫により、計算を大幅に削減し、「厳密に1番近いものではないかもしれないが、実用上問題ないレベルで非常に近いもの」を高速に見つけ出します。
【エンジニアの活用シーン(Use Case)】
エンジニアが直接このアルゴリズムを実装することは稀です。性能チューニングの際に、ANNのパラメータを調整することがあります。
ステップ4:応用技術・開発手法 (RAG, ファインチューニング, LangChain)
これまでの技術を組み合わせて、より高度なAIアプリケーションを作るための「設計図」を描くステップです。高性能な大規模言語モデル(LLM)も、そのままだと会社の内部情報や最新のニュースを知らないため、ビジネスに活用しにくいという課題があります。
ここでは、その課題を解決し、LLMを特定の目的に特化させるための代表的なアプローチである「RAG」と「ファインチューニング」、そしてそれらの実装を助ける「開発フレームワーク」について取り上げます。
RAG (Retrieval-Augmented Generation)
【概念(What?)】
LLMが回答を生成(Generation)する際に、まず外部のデータベースから関連情報を検索(Retrieval)し、その内容を参考にして回答を生成させる仕組み
【意味合い(Why/How?)】
LLM単体では、学習データに含まれない最新情報や、社内情報のような非公開情報については答えられず、もっともらしい嘘(ハルシネーション)をつくことがあります。RAGは、ベクトル検索などで正確な情報を「カンペ」としてLLMに渡すことで、根拠に基づいた信頼性の高い回答を生成させることができます。
【エンジニアの活用シーン(Use Case)】
- 自社の膨大なマニュアルをデータベース化し、顧客からの問い合わせに正確に答えるカスタマーサポートAIを構築する
- 最新の決算情報やニュースリリースを読み込ませ、投資家からの質問に答えるIR用チャットボットを開発する
ファインチューニング
【概念(What?)】
既存の学習済みモデルを特定のデータセットで追加学習させること
【意味合い(Why/How?)】
モデルに特定の専門知識や、企業独自の応答スタイルなどを「刷り込む」ことができます。汎用モデルを特化させるためのチューニングです。RAGが「外付けの知識」で対応するのに対し、ファインチューニングは「モデル自身の知識・能力」を向上させるアプローチです。
【エンジニアの活用シーン(Use Case)】
- 医療分野の論文応答用にLLMをファインチューニングする
- 特定のキャラクターの口調で話すチャットボットを作成する
LangChain
【概念(What?)】
RAGのような、複数のコンポーネントを連携させるLLMアプリケーションを、効率的に開発するためのフレームワーク(道具箱)
【意味合い(Why/How?)】
「データを読み込む→テキストを分割する→ベクトル化する→DBに保存する→ユーザーの質問をベクトル化する→ベクトル検索する→検索結果と質問をLLMに渡す→回答を得る」というRAGの一連の複雑な処理を、あらかじめ用意された部品を繋ぎ合わせるように、数行のコードで記述できます。
【エンジニアの活用シーン(Use Case)】
- RAGアプリケーションのプロトタイプを迅速に開発し、PoC(概念実証)を行う
- LLMにWeb検索機能や計算機能など、複数の外部ツールを連携させる「AIエージェント」を構築する
ステップ5:実現するための道具(ミドルウェア) (OpenSearch)
設計図を元に、実際にアプリケーションを構築・実行するための「ソフトウェア基盤」です。高度な検索機能をゼロから実装するのは非常に大変ですが、このミドルウェアを利用することで、開発者は複雑な処理を意識することなく、強力な検索・分析機能をアプリケーションに組み込むことができます。
ここで紹介するOpenSearchのような検索エンジンは、まさにその代表例です。これらは、ステップ2で見た古典的なキーワード検索(TF-IDFなど)と、ステップ3で見た最新のベクトル検索の両方を実行できる強力な実行基盤です。
OpenSearch
【概念(What?)】
キーワード検索(全文検索)とベクトル検索の両方を実行できる、非常に強力で多機能な検索プラットフォーム。もともとはElasticsearchから派生(フォーク)して生まれたプロジェクトで、AWSが中心となりコミュニティベースで開発が進められている
【意味合い(Why/How?)】
元々はログ分析や全文検索で絶大なシェアを誇っていましたが、近年ベクトル検索機能も大幅に強化されました。一つのミドルウェアでハイブリッド検索を実現できる点や、豊富な分析・可視化機能を持つ点が強みです。「検索の百貨店」のように、あらゆる検索・分析ニーズに応えられます。
- 全文検索: TF-IDF/BM25といった古典的なアルゴリズムを用いた、高速で強力なキーワード検索機能が基盤となっています
- ベクトル検索: 近年、k-NN(k-近傍法)によるベクトル検索機能が大幅に強化され、AIを活用したセマンティック検索や画像検索などのユースケースにも対応できます
【エンジニアの活用シーン(Use Case)】
- ECサイトの検索基盤として導入し、商品名でのキーワード検索と、商品説明文からのベクトル検索を組み合わせて利用する
- Webサーバーのアクセスログをリアルタイムに収集・分析し、ダッシュボードで可視化してサービス監視を行う
まとめ:キーワードの関係性を整理
最後に、今回登場したキーワードたちの関係性を図で整理してみます。
各要素の構造的な流れ
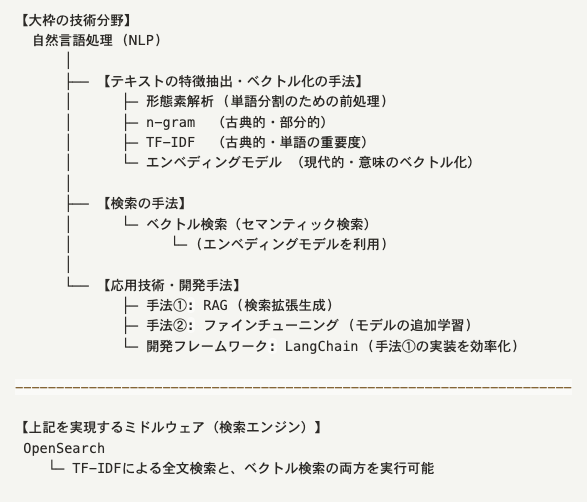
ユーザーの入力からの流れ(例)

おわりに
本記事では、自然言語処理の重要技術を、前処理から応用までの一連の流れに沿って解説してきました。
私はこれらのキーワードをいまいち理解できていなかったのですが、一つ一つの技術の役割と繋がりをこうして整理することで、線として少し理解が深まりました。この記事を通して、個々のキーワードの各概念(点)の理解を深め、「線」として繋がるきっかけになれたら幸いです。
最後までお読みいただきありがとうございました!
Views: 0

{kind=link}