

こんなAIエージェントをGUIで作成します!

あなたの質問に、Lambda関数やRAGを駆使して答えてくれます。

挫折しづらいように、過去最高にLambda周りの設定要素を抑えました!
AWSアカウントを作成して、サインインします。
以降、このハンズオンで作業するリージョンは以下をおすすめします。
- バージニア北部 or オレゴン:最新機能が使える。モデルAPIのクォータが緩い
- 東京:他国よりは比較的、新しい機能が使える。海外リージョンが使えない方はこちら
Bedrockコンソール左下の「モデルアクセス」をクリック
オレンジ色の「Enable all models」をクリック

すべてのモデルがチェックされている状態で、画面右下のオレンジ色「Next」をクリック

有効にしたモデルの数ぶん、AWS Marketplaceのサブスクライブ通知メールが飛んできますが驚かないで大丈夫です。
もちろん必要なモデルのみにチェックを絞ってもOKです。今回使用するモデルは以下です。
- Anthropic > Claude 3.5 Sonnet v2
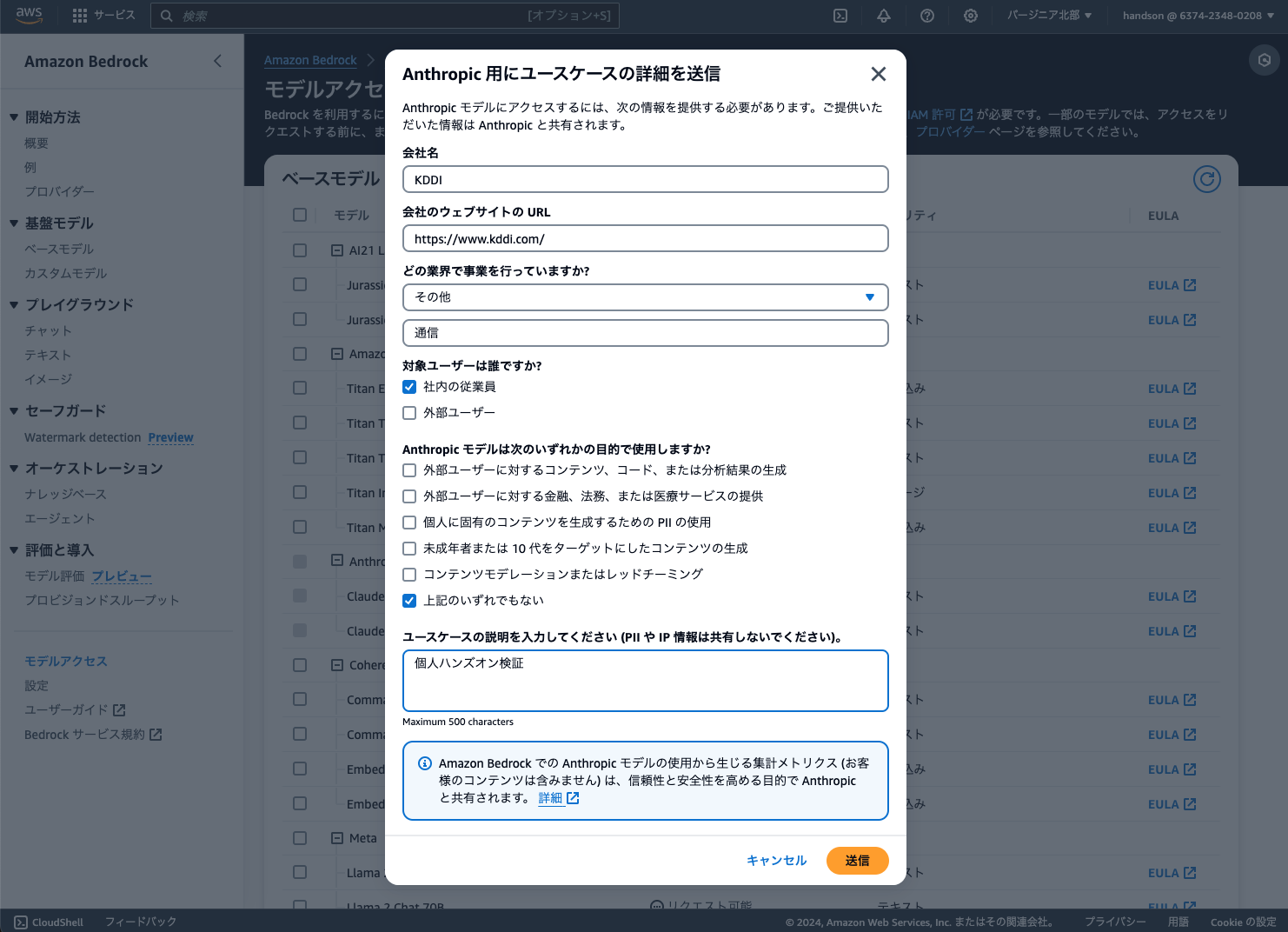
次のステップでは、Anthropic社の要件により、モデル用途を記載する必要があります。(ざっくりでOK)
- 会社名: あなたの所属会社名
- 会社サイトのURL: あなたの会社のHPなど
- 業界: あなたの会社の所属業界名
- 対象ユーザー:
社内の従業員のみにチェック - ユースケースの説明:
個人検証など
上記を記載し「送信」をクリック ※以下の画面は少し古いものなので参考です。
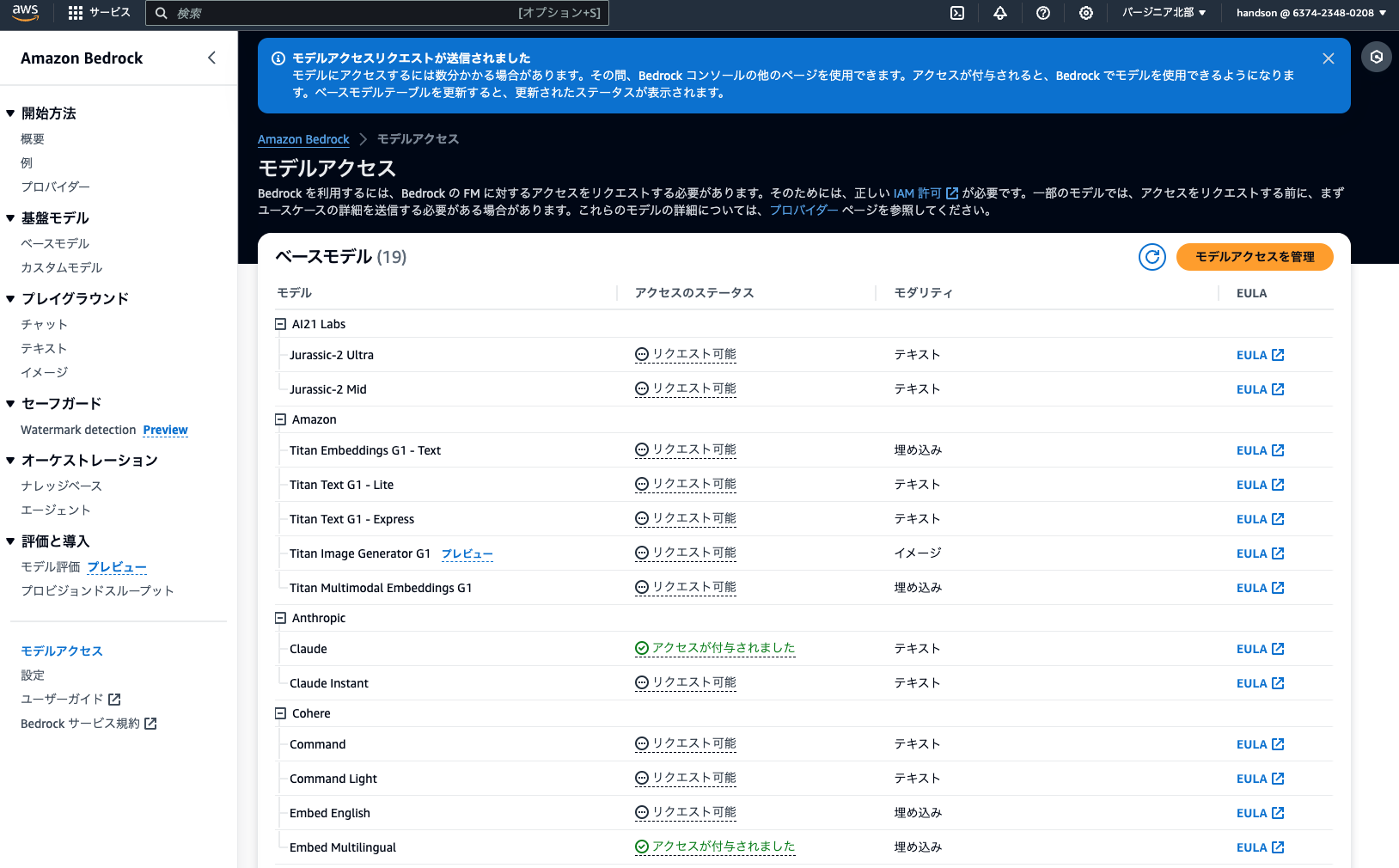
最後の確認画面で、画面右下のオレンジ色「Submit」をクリック
※1〜2分待つと、選択したモデルが「アクセスが付与されました」ステータスに変わります。右上の更新ボタンでリロードできます。
3-1. エージェントの作成
Bedrockコンソール > エージェント > エージェントを作成

作成後、エージェントビルダーで以下設定
- モデルを選択: Anthropic > Claude 3.5 Sonnet v2 > US Anthropic Claude 3.5 Sonnet v2
- エージェント向けの指示:
あなたはフレンドリーで賢いAIアシスタントです。祝日について聞かれたら、アクショングループを使ってください。必要あればナレッジベースの知識も参照してください。
ここで一度「保存」を押す。
3-2. アクショングループの追加
エージェントビルダーの画面中段から追加します。
- アクショングループ名:
get_holidays - アクショングループ関数1
- パラメータ:以下のとおり。
| 名前 | 説明 | タイプ | 必須 |
|---|---|---|---|
| year | 年 | String | True |
入力後「作成」をクリック。
3-3. 【オプション】ナレッジベースの追加
以下のハンズオンを実施した方は、作成したナレッジベースを追加してみましょう。
エージェントビルダーの画面中段から追加します。
- ナレッジベースを選択: 作成したナレッジベース名を指定する
- エージェント向けのナレッジベースの指示:
xxxについて知りたいときは、このナレッジベースを参照してください。(自分が使ったデータに合わせてxxx部分を更新してください)
3-4. エージェントのデプロイ
エージェントビルダーを「保存して終了」しておく。
Webで公開されているAPIを叩いて、日本の祝日情報を取得する関数を作成します。
Lambdaコンソールに移動し、関数 get_holidays-xxxxx をクリック。
コードソースの「dummy_lambda.py」関数を以下コードで上書きする。
dummy_lambda.py
import json
import urllib.request
def lambda_handler(event, context):
# パラメータから年を取得
for p in event.get('parameters', []):
if p.get('name') == 'year':
year = p.get('value')
# 祝日データを取得
url = f"https://holidays-jp.github.io/api/v1/{year}/date.json"
with urllib.request.urlopen(url) as response:
holidays = json.loads(response.read())
# 結果を整形
text = f"{year}年の日本の祝日:\n"
for date, name in sorted(holidays.items()):
text += f"{date}: {name}\n"
# Bedrockエージェント用のレスポンス
return {
'response': {
'actionGroup': event['actionGroup'],
'function': event['function'],
'functionResponse': {
'responseBody': {
'TEXT': {'body': text}
}
}
},
'messageVersion': event.get('messageVersion', 1)
}
上書き後、忘れずに「Deploy」ボタンを押す。
5-1. 動作テスト
Bedrockエージェントの画面に戻り、作成した「holidays-agent」をクリック。

右側のテストサイドバーの「準備」をクリック。
ナレッジベースにあるプレスリリースの発行日は、日本の祝日に該当する? といった質問を送信してみましょう。
アクショングループとナレッジベースの両方を使うような質問が理想です。
また、以下のエラーはナレッジベースのベクトルDB(Aurora)がスリープしていると発生します。1分ほど待ってリトライしましょう。
The vector database encountered an error while processing the request: The Aurora DB instance db-PMGZLMADG5B7DCBFDM3CI2GXVM is resuming after being auto-paused. Please wait a few seconds and try again.
5-2. デプロイ
うまくいったら「エイリアスの作成」を実施。
- エイリアス名:
1など(何でもよい)

6-1. フロントエンドの開発
マネコン上部の検索バーから「CloudShell」を検索して右クリックし、新しいタブで開きます。

以下のコマンドを実行しましょう。
nanoというシンプルなテキストエディターで、フロントエンド用のPythonファイルを新規作成します。
以下のコードを、そのままコピーしてnanoに貼り付けましょう。
agent.py
import os, json, uuid, boto3
import streamlit as st
from botocore.exceptions import ClientError
from botocore.eventstream import EventStreamError
def initialize_session():
"""セッションの初期設定を行う"""
if "client" not in st.session_state:
st.session_state.client = boto3.client("bedrock-agent-runtime")
if "session_id" not in st.session_state:
st.session_state.session_id = str(uuid.uuid4())
if "messages" not in st.session_state:
st.session_state.messages = []
if "last_prompt" not in st.session_state:
st.session_state.last_prompt = None
if "agent_id" not in st.session_state:
st.session_state.agent_id = ""
if "agent_alias_id" not in st.session_state:
st.session_state.agent_alias_id = ""
return st.session_state.client, st.session_state.session_id, st.session_state.messages
def display_chat_history(messages):
"""チャット履歴を表示する"""
st.title("おしえて! Bedrockエージェント")
st.text("Lambdaとナレッジベースを使いこなして、質問に答えます")
for message in messages:
with st.chat_message(message['role']):
st.markdown(message['text'])
def handle_trace_event(event):
"""トレースイベントの処理を行う"""
if "orchestrationTrace" not in event["trace"]["trace"]:
return
trace = event["trace"]["trace"]["orchestrationTrace"]
# 「モデル入力」トレースの表示
if "modelInvocationInput" in trace:
with st.expander("🤔 思考中…", expanded=False):
input_trace = trace["modelInvocationInput"]["text"]
try:
st.json(json.loads(input_trace))
except:
st.write(input_trace)
# 「モデル出力」トレースの表示
if "modelInvocationOutput" in trace:
output_trace = trace["modelInvocationOutput"]["rawResponse"]["content"]
with st.expander("💡 思考がまとまりました", expanded=False):
try:
thinking = json.loads(output_trace)["content"][0]["text"]
if thinking:
st.write(thinking)
else:
st.write(json.loads(output_trace)["content"][0])
except:
st.write(output_trace)
# 「根拠」トレースの表示
if "rationale" in trace:
with st.expander("✅ 次のアクションを決定しました", expanded=True):
st.write(trace["rationale"]["text"])
# 「ツール呼び出し」トレースの表示
if "invocationInput" in trace:
invocation_type = trace["invocationInput"]["invocationType"]
if invocation_type == "KNOWLEDGE_BASE":
with st.expander("📖 ナレッジベースを検索中…", expanded=False):
st.write(trace["invocationInput"]["knowledgeBaseLookupInput"]["text"])
elif invocation_type == "ACTION_GROUP":
with st.expander("💻 Lambdaを実行中…", expanded=False):
st.write(trace['invocationInput']['actionGroupInvocationInput'])
# 「観察」トレースの表示
if "observation" in trace:
obs_type = trace["observation"]["type"]
if obs_type == "KNOWLEDGE_BASE":
with st.expander("🔍 ナレッジベースから検索結果を取得しました", expanded=False):
st.write(trace["observation"]["knowledgeBaseLookupOutput"]["retrievedReferences"])
def invoke_bedrock_agent(client, session_id, prompt, agent_id, agent_alias_id):
"""Bedrockエージェントを呼び出す"""
return client.invoke_agent(
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=session_id,
enableTrace=True,
inputText=prompt,
)
def handle_agent_response(response, messages):
"""エージェントのレスポンスを処理する"""
with st.chat_message("assistant"):
for event in response.get("completion"):
if "trace" in event:
handle_trace_event(event)
if "chunk" in event:
answer = event["chunk"]["bytes"].decode()
st.write(answer)
messages.append({"role": "assistant", "text": answer})
def show_error_popup(exeption):
"""エラーポップアップを表示する"""
if exeption == "dependencyFailedException":
error_message = "【エラー】ナレッジベースのAurora DBがスリープしていたようです。しばらく待ってから、ブラウザをリロードして再度お試しください🙏"
elif exeption == "throttlingException":
error_message = "【エラー】Bedrockのモデル負荷が高いようです。1分後にブラウザをリロードして再度お試しください🙏(改善しない場合は、モデルを変更するか[サービスクォータの引き上げ申請](https://aws.amazon.com/jp/blogs/news/generative-ai-amazon-bedrock-handling-quota-problems/)を実施ください)"
st.error(error_message)
def main():
"""メインのアプリケーション処理"""
client, session_id, messages = initialize_session()
# サイドバーにエージェント設定を配置
with st.sidebar:
st.session_state.agent_id = st.text_input("エージェントのID", value=st.session_state.agent_id)
st.session_state.agent_alias_id = st.text_input("エージェントのエイリアスID", value=st.session_state.agent_alias_id)
display_chat_history(messages)
# エージェントIDとエイリアスIDが設定されている場合のみチャット入力を表示
if st.session_state.agent_id and st.session_state.agent_alias_id:
if prompt := st.chat_input("質問してね"):
messages.append({"role": "human", "text": prompt})
with st.chat_message("user"):
st.markdown(prompt)
try:
response = invoke_bedrock_agent(client, session_id, prompt, st.session_state.agent_id, st.session_state.agent_alias_id)
handle_agent_response(response, messages)
except (EventStreamError, ClientError) as e:
if "dependencyFailedException" in str(e):
show_error_popup("dependencyFailedException")
elif "throttlingException" in str(e):
show_error_popup("throttlingException")
else:
raise e
else:
st.info("最初にサイドバーでエージェントIDとエイリアスIDを設定してください")
if __name__ == "__main__":
main()
貼り付け後、エディターを保存して閉じるために以下のキーを順番に入力します。
- エディターの終了:
Ctrl + x - 変更を保存しますか?:
y - ファイル名はこれでいいですか?:
Enter

6-2. フロントエンドの起動
以下コマンドで、必要なPythonライブラリをインストールします。
CloudShell
pip install boto3 streamlit
その後、フロントエンドを起動しましょう。
Streamlitのアクセス用URLが表示されたら、うまく起動しています。

6-3. 作ったアプリへアクセスしてみよう
CloudShell上部の「+」をクリックし、2つ目の「us-east-1」ターミナルを起動して以下を実行します。
CloudShell
ssh -p 443 -R0:localhost:8501 a.pinggy.io
確認メッセージが出力されたら yes と入力してEnterを押すと、Pinggyという外部サービスを通じてこのアプリにアクセス可能なURLが発行されます。
下側のHTTPSの方のURLをコピーして、ブラウザの別タブからアクセスしてみましょう。

赤色の「Enter site」をクリックすると、先ほどアップロードしたPythonアプリにアクセスできます。Streamlitというフレームワークを使って、フロントエンドを表示しています。
参考まで、以下のような仕組みでCloudShell上のPythonアプリににアクセスしています。

以下のようなStreamlitのWeb画面が表示されます。
実際にこのアプリを使ってみましょう。
先ほど作ったエージェントの概要画面から「ID」と「エイリアスID」をコピーして、アプリに入力します。

その後、質問フォームを入力してみましょう。
もしエラーメッセージが表示された際は、1分ほど待ってから再実行してみてください。
- 今回利用するAurora Serverlessは、一定時間アクセスがないと自動でスリープする「ゼロスケール」に対応しているため、復帰に1分程度かかることがあります。
- 新規作成したAWSアカウントでは、Claude APIの分間レートリミットが厳しめです。
あなたのCloudShell上で、このStreamlitアプリを実行している間であれば、PinggyのURLを共有するだけで同僚にもこのアプリを使ってもらうことができます。
繰り返しますが、このURLが第三者に知られるとあなたのCloudShellにアクセス可能となってしまうため、セキュリティ上のリスクがあることをご認識ください。
URLを同僚に共有する場合は慎重に行い、ハンズオン終了後は速やかに環境の停止・削除を実施ください。
(なおPinggyは無料版の制約として、60分経つとURLが無効となります)
AWSアカウントによってはBedrockのモデル呼び出し初期クォータが低く、スロットリングエラーが発生してしまうことがあります。
その場合は、エージェントビルダーからモデルを変更し、再度エイリアスを発行して試してみてください。
おすすめの代替モデル:
- Anthropic > Claude 3 Sonnet
- Amazon > Nova Premium
AWSサポートに問い合わせることで、上限緩和が可能なことがあります。
今回作ったアプリをコンテナにしてWeb公開してみる
マルチエージェントにも挑戦してみる
LLMOps(監視と評価)に入門してみる
Bedrockにちゃんと入門してみたくなったら…

MCPの入門書も出版します! すでにアマゾン等で予約可能。

Views: 0

{kind=link}