
はじめに
次の 2 つの記事では、ADK で会話型エージェントを作る基本的な方法、そして、マルチエージェントの基本となるアーキテクチャーを学びました。この後の説明では、これらの記事で説明した用語が登場するので、まずはこれらの記事に目を通しておくことをお勧めします。
今回の記事では、次のステップとして、画像ファイルなどのマルチメディアを取り扱うエージェントを作成します。Gemini API から単体の LLM を利用することで画像解析などができますが、このような機能を会話型のインターフェースで利用することを目指します。
ここでは一例として、クラウドストレージに保存された画像ファイルを分析する「メディアエージェント」を作成します。このエージェントは、クラウドストレージ内のファイルを動的に検索しながらユーザーの依頼に応えます。ファイル名を指定して画像を表示したり、画像の内容を文章で説明するなどの使い方が考えられます。

メディアエージェントの利用イメージ
メディアエージェントのアーキテクチャー
エージェントが利用するツールの設計
このエージェントは、どのようにして画像ファイルを分析するのでしょうか? ADK のエージェントは内部に LLM を備えているので、エージェント自身の LLM で画像を分析することもできそうですが、これはあまりよい設計とは言えません。ADK のエージェントの第一の役割は、ユーザーの入力テキストに対して、これまでの会話の流れを勘案した上で、どのような処理をするべきかを判断することです。 実際の処理内容、すなわち、実行するべきタスクを決定した後は、該当の処理に特化した専用のツールやサブエージェントに処理を依頼するのが適切です。
この際にポイントになるのが、どのような粒度でタスクをわけるべきかという点です。 先ほどの例では、「画像の内容を説明する」というタスクを実行しましたが、このほかにも「画像内のテキストを読み取る」「画像にタグ付けする」などさまざまなタスクが考えられます。このようなタスクごとに個別のツールを用意する方法もありますが、あまり細かく分けすぎると、システム構成が複雑になるというデメリットも生まれます。
また、ユーザーが利用する可能性がある機能をはじめから網羅するのも困難です。会話型のアプリケーションの場合、ユーザーはさまざまな処理を自由に依頼できるので、考えられるすべての依頼内容を個別のタスクとして用意することは不可能です。このような状況に対処するには、はじめは、複数のタスクに対応した汎用性の高いツールを用意しておき、ユーザーの利用状況を見ながら、高い精度が求められるタスクについては、個別のツールを追加していくという戦略が考えられます。
今回の例では、まずは、「LLM(Gemini API)を利用して画像を分析する」という汎用のツールを用意しておき、分析内容については、LLM に与えるシステムインストラクションで自由に指定できるようにします。システムインストラクションの内容は、ADK のエージェント(ルートエージェント)がユーザーの依頼に応じて考えます。
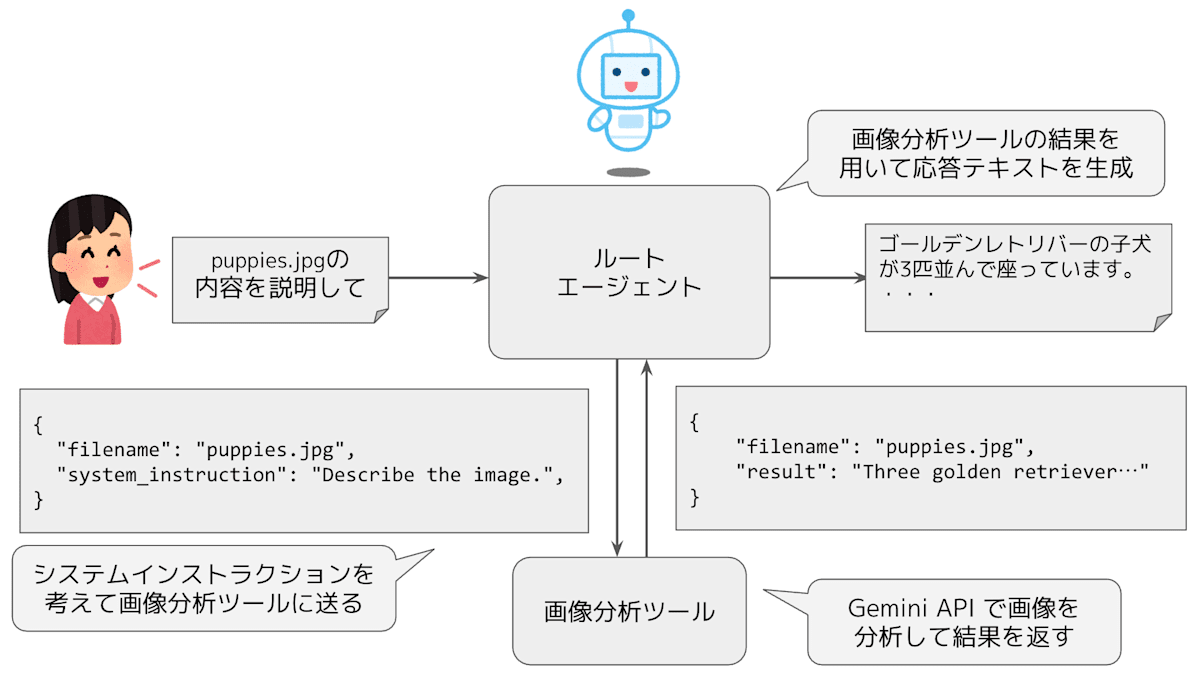
画像分析ツールを用いたアーキテクチャー
この後の実装例で説明するように、この他には、ストレージバケット内のファイル名一覧を取得するツールも用意します。複数のツールをエージェントに登録した場合、エージェントは、ツールの定義に含まれるドキュメントストリングからツールの役割を理解して、どの場面でどのツールを利用するかを判断します。エージェントに対する instruction で指示することもできます。
画像表示機能の実現方法
冒頭のイラスト「メディアエージェントの利用イメージ」では、エージェントの応答には画像とテキストが含まれていました。ADK のエージェントの出力は基本的にはテキストのみですので、画像を表示する部分はフロントエンドのアプリケーションで実装します。
今回は、エージェントに対して、応答文の中に画像を挿入する場合は、該当部分に _filename_ は実際のファイル名に置き換える)という文字列を埋め込むように指示します。フロントエンドのアプリケーションは、エージェントが出力したテキストを画面表示する際に、ストレージバケット内の対応する画像ファイルを使って、該当の文字列を実際の画像に置き換えます。
メディアエージェントの実装
それでは、前述の機能を持ったメディアエージェントと、このエージェントと会話するアプリケーションを実装していきます。アプリケーションについては、ノートブック上で利用する簡易的な実装を用いますが、ブラウザーから利用できる Web アプリケーションを作ることもそれほど難しくはないでしょう。
環境準備
Vertex AI workbench のノートブック上で実装しながら説明するために、まずは、ノートブックの実行環境を用意しましょう。新しいプロジェクトを作成したら、Cloud Shell のコマンド端末を開いて、必要な API を有効化します。
gcloud services enable
aiplatform.googleapis.com
notebooks.googleapis.com
cloudresourcemanager.googleapis.com
続いて、Workbench のインスタンスを作成します。
PROJECT_ID=$(gcloud config list --format 'value(core.project)')
gcloud workbench instances create agent-development
--project=$PROJECT_ID
--location=us-central1-a
--machine-type=e2-standard-2
クラウドコンソールのナビゲーションメニューから「Vertex AI」→「Workbench」を選択すると、作成したインスタンス agent-develpment があります。インスタンスの起動が完了するのを待って、「JUPYTERLAB を開く」をクリックしたら、「Python 3(ipykernel)」の新規ノートブックを作成します。
初期設定
ここからは、ノートブックのセルでコードを実行していきます。
はじめに、Agent Development Kit (ADK) のパッケージをインストールします。
%pip install --upgrade --user google-adk
インストールしたパッケージを利用可能にするために、次のコマンドでカーネルを再起動します。
import IPython
app = IPython.Application.instance()
_ = app.kernel.do_shutdown(True)
再起動を確認するポップアップが表示されるので [Ok] をクリックします。
次に、必要なモジュールをインポートして、実行環境の初期設定を行います。
import json, os, re, uuid
import vertexai
from google.cloud import storage
from google import genai
from google.genai.types import (
HttpOptions, GenerateContentConfig,
Part, UserContent, ModelContent
)
from google.adk.agents.llm_agent import LlmAgent
from google.adk.artifacts import InMemoryArtifactService
from google.adk.memory.in_memory_memory_service import InMemoryMemoryService
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
[PROJECT_ID] = !gcloud config list --format 'value(core.project)'
LOCATION = 'us-central1'
vertexai.init(project=PROJECT_ID, location=LOCATION)
os.environ['GOOGLE_CLOUD_PROJECT'] = PROJECT_ID
os.environ['GOOGLE_CLOUD_LOCATION'] = LOCATION
os.environ['GOOGLE_GENAI_USE_VERTEXAI'] = 'True'
BUCKET_NAME = f'{PROJECT_ID}-adk-media'
最後の変数 BUCKET_NAME は、画像ファイルを保存するストレージバケットを指定します。必要に応じて変更しても構いません。次のコマンドで、バケットを作成します。
!gsutil mb -b on -l {LOCATION} gs://{BUCKET_NAME}
作成したバケットにサンプルの画像ファイルを保存します。
photos = [
'duck_and_truck.jpg', 'handwritten.jpg',
'puppies.jpg', 'eiffel_tower.jpg',
]
photo_uris = ' '.join([f'gs://cloud-samples-data/vision/{item}' for item in photos])
!gsutil -m cp {photo_uris} gs://{BUCKET_NAME}/
pictures = [
'https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhhuTPpp1ITtm1efWPA5Ke1V1uWz7-9lniIP0goxnFNgPlaiA33A6K_fX8bpQ8VGroVmrgkQl5pzfRZbwZNGXEAXnMvT3WIPOagILsEfLWOKkOv6jdmRwNCliI2XX9NiFoqLygN4_VNxFx2/s400/jitensya_papa_3nin2.png',
'https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi6ZNtzo3MbPW5OkKXkD-tliX2CTkMEQpVBiwb6LocZF1MjaNP3Sm7rY7Uh1xfECAYojFT_FpsHZ7Nr7nshNqep8gfZQARoW5mJIswuIwa2AJxaIEiq87W76EVf3PyR160x9XCWM1P0bgyX/s450/jitensya_papa_3nin_dendo.png'
]
picture_urls = ' '.join([f'-O {item}' for item in pictures])
picture_files = ' '.join([item.split("https://zenn.dev/")[-1] for item in pictures])
!curl -L {picture_urls}
!gsutil cp {picture_files} gs://{BUCKET_NAME}/
ここでは、写真画像 photos とイラスト画像 pictures を混ぜて保存しています。
補助関数の定義
ツール、および、アプリケーションが内部で利用する補助関数を用意します。
次の generate_response() は、Gemini API で、単体の LLM として Gemini を利用する関数です。
def generate_response(system_instruction, contents,
response_schema, model='gemini-2.0-flash-001'):
client = genai.Client(vertexai=True,
project=PROJECT_ID, location=LOCATION,
http_options=HttpOptions(api_version='v1'))
response = client.models.generate_content(
model=model,
contents=contents,
config=GenerateContentConfig(
system_instruction=system_instruction,
temperature=0.4,
response_mime_type='application/json',
response_schema=response_schema,
)
)
return 'n'.join(
[p.text for p in response.candidates[0].content.parts if p.text]
)
実行例は、次のようになります。
system_instruction = '''
関西のお笑い芸人としてリクエストに答えてください。
'''
contents = 'ノリツッコミよろしく!'
response_schema = {
"type": "object",
"properties": {
"nori": {"type": "string"},
"tsukkomi": {"type": "string"},
},
"required": ["nori", "tsukkomi"],
}
response = generate_response(system_instruction, contents, response_schema)
print(response)
[出力結果]
{
"nori": "はい、毎度!今日はですね、わたくし、あの、宇宙旅行に行ってきたんですよ!",
"tsukkomi": "いや、行ってへんやろ!どこにそんな金があんねん!それに、お前、閉所恐怖症やないか!"
}
次の display_image は、バケット内の画像ファイルをノートブックの画面上に表示します。
from PIL import Image
from io import BytesIO
import matplotlib.pyplot as plt
def display_image(blob_name, title, bucket_name=BUCKET_NAME):
client = storage.Client()
bucket = client.bucket(bucket_name)
image_bytes = bucket.blob(blob_name).download_as_bytes()
img = Image.open(BytesIO(image_bytes))
fig, ax = plt.subplots(figsize=(4, 4))
ax.imshow(img)
ax.set_title(title, fontsize=10)
ax.axis('off')
実行例は、次のようになります。
display_image('puppies.jpg', 'Image - puppies.jpg')
[出力結果]
ツール関数の定義
続いて、ADK のエージェントが利用するツールの関数を用意します。
次の list_image_files() は、バケット内のファイルの一覧を取得します。
def list_image_files() -> dict:
"""Tool to list available image files for the user."""
try:
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
blobs = bucket.list_blobs()
return {'files': [blob.name for blob in blobs if not blob.name.endswith("https://zenn.dev/")]}
except Exception as e:
return {'error': e}
実行例は、次のようになります。
response = list_image_files()
print(response)
[出力結果]
{'files': ['duck_and_truck.jpg', 'eiffel_tower.jpg', 'handwritten.jpg', 'jitensya_papa_3nin2.png', 'jitensya_papa_3nin_dendo.png', 'puppies.jpg']}
次の analyze_image() は、先ほど用意した generate_response() を用いて、バケット内の特定のファイルを Gemini で分析します。
def analyze_image(system_instruction: str, filename: str):
"""
Tool to analyze an image using LLM.
Args:
system_instruction (str): Instruction to LLM on how to analyze an image
filename (str): Filename of an image
Returns:
dict: A dictionary containing the plan with the following keys:
filename: Filename of an image
result: Result of the analysis
"""
try:
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
blob = bucket.blob(filename)
blob.reload()
mime_type = blob.content_type
image = Part.from_uri(
file_uri=f'gs://{BUCKET_NAME}/{filename}',
mime_type=mime_type
)
parts = []
parts.append(Part.from_text(text='[image]'))
parts.append(image)
contents = contents=[UserContent(parts=parts)]
response_schema = {
"type": "object",
"properties": {
"filename": {"type": "string"},
"result": {"type": "string"},
},
"required": ["filename", "result"],
}
result = generate_response(
system_instruction, contents,
response_schema, model='gemini-2.0-flash-001'
)
return json.loads(result)
except Exception as e:
return {
'filename': filename,
'result': f'An unexpected error occurred: {e}'
}
実行例は、次のようになります。
response = analyze_image('何の画像か日本語で説明して。', 'puppies.jpg')
print(response)
[出力結果]
{'filename': 'image.png',
'result': 'ゴールデンレトリバーの子犬が3匹並んで座っています。みんな舌を出してカメラをまっすぐ見ています。背景は緑の葉がぼやけています。'}
会話アプリケーションの作成
続いて、ADK で作成したエージェントと会話するためのアプリケーションのクラス LocalApp を用意します。
class LocalApp:
def __init__(self, agent, app_name='local_app', user_id='default_user'):
self._agent = agent
self._user_id = user_id
self._app_name = app_name
self._runner = Runner(
app_name=self._app_name,
agent=self._agent,
artifact_service=InMemoryArtifactService(),
session_service=InMemorySessionService(),
memory_service=InMemoryMemoryService(),
)
self._session = self._runner.session_service.create_session(
app_name=self._app_name,
user_id=self._user_id,
state={},
session_id=uuid.uuid1().hex,
)
def _display_image(self, text, num_images):
def replace(match):
nonlocal num_images
num_images += 1
return f'## Displayed image [{num_images}] ##'
pattern = '(.+?) '
matches = re.findall(pattern, text)
for c, filename in enumerate(matches):
title = f'[{num_images+c+1}] {filename}'
display_image(filename, title)
text = re.sub(pattern, replace, text)
return text, num_images
async def stream(self, query):
content = UserContent(parts=[Part.from_text(text=query)])
async_events = self._runner.run_async(
user_id=self._user_id,
session_id=self._session.id,
new_message=content,
)
result = []
num_images = 0
async for event in async_events:
if DEBUG:
print(f'----n{event}n----')
if (event.content and event.content.parts):
response = ''
for p in event.content.parts:
if p.text:
text, num_images = self._display_image(p.text, num_images)
if text:
response += f'[{event.author}]nn{text}n'
if response:
print(response)
result.append(response)
return result
具体的な利用例はこの後で紹介しますが、LocalApp クラスのインスタンスを生成して、ユーザーからの入力テキストを stream() メソッドに渡すと、エージェントからの応答が表示されます。内部メソッド _display_image() は、応答テキストに含まれる ## Displayed image [画像番号] ## という文字列に置き換えて、対応する画像番号をタイトルに含む画像を出力の最後に表示します。本来は、
メディアエージェントの実装
それではいよいよ、ADK でメディアエージェントを実装します。—— といっても、ここまでの準備ができていれば、とても簡単です。先に用意した list_image_files() と analyze_image() をツールとして登録したエージェント image_manager_agent を次のように定義します。
image_manager_agent = LlmAgent(
name='image_manager_agent',
model='gemini-2.0-flash',
instruction='''
You are an agent that manages image files.
Output in Japanese without markdowns.
[conditions]
* Before working on tasks, explain what you will do in a short single sentence.
* Avoid mentioning tool names in your reply.
* Show underscore in filenames as "_" instead of "_".
- Good example: "my_file.png"
- Bad example: "my_file.png"
[tasks]
** List image files
* You can get a list of image files with the tool "list_image_files".
** Display image
* You can insert an image in your message by inserting a line "_filename_ ".
Replace _filename_ with the filename of the image file.
Then the user will see the real image in that part.
** Analyze image
* If you need to analyze an image, use the tool "analyze_image".
''',
description='''
An agent that manage image files.
''',
tools = [
list_image_files,
analyze_image,
]
)
instruction オプションの内容を見ると、このエージェントが実行するべきタスクと利用するべきツールが詳しく記述されています。それぞれのツールの使い方は、対応する関数の定義に含まれる型アノテーションやドキュメントストリングから自動的に理解します。画像を出力する際は
メディアエージェントの利用例
基本機能の確認
さっそく、メディアエージェントを利用してみましょう。まずは、用意したツール list_image_files と analyze_image のそれぞれを利用した処理を依頼してみます。
次のように、先に用意したエージェントのインスタンス image_manager_agent を指定して、LocalApp クラスのインスタンスを生成した上で、stream() メソッドを利用します。
client = LocalApp(image_manager_agent)
DEBUG = False
query = '''
画像ファイルは全部で何個ありますか?
10個以下ならファイル名をすべて表示して。
'''
_ = await client.stream(query)
[出力結果]
[image_manager_agent]
画像ファイルが何個あるか確認し、10個以下であればファイル名をすべて表示します。
[image_manager_agent]
画像ファイルは全部で6個です。ファイル名は以下の通りです。
duck_and_truck.jpg
eiffel_tower.jpg
handwritten.jpg
jitensya_papa_3nin2.png
jitensya_papa_3nin_dendo.png
puppies.jpg
出力結果に含まれる [image_manager_agent] は、この出力を生成したエージェントの名前です。サブエージェントを含むマルチエージェント構成の場合、ステップごとに処理を行うエージェントが切り替わることがありますが、今回の場合は、すべてのステップを image_manager_agent が実行します。
また、ここでは、バケットに保存されたファイルの一覧を取得しています。ファイルが大量にあると出力が長くなって困るので、念のために 10 個以下であることを確認しています。DEBUG=True を指定して実行すると、裏側で、ツール list_image_files を利用していることが確認できます。
次は、それぞれの画像ファイルの内容を確認します。
query = '''
それぞれの内容を簡単に短くまとめて、箇条書きで教えて。
'''
_ = await client.stream(query)
[出力結果]
[image_manager_agent]
各画像の内容を分析して、箇条書きで説明します。
[image_manager_agent]
各画像の内容をまとめました。
* duck_and_truck.jpg: 黄色いアヒルのおもちゃとカラフルなダンプカーがおもちゃとして置かれている画像です。
* eiffel_tower.jpg: 曇りの日のエッフェル塔とセーヌ川の画像です。
* handwritten.jpg: Google Cloud Vision API の手書き文字認識機能を示すための手書きメッセージの画像です。
* jitensya_papa_3nin2.png: 自転車に子供二人を乗せて走る父親の画像です。
* jitensya_papa_3nin_dendo.png: 電動自転車に子供二人を乗せて走る父親の画像です。
* puppies.jpg: 3匹のゴールデンレトリバーの子犬が並んで座り、舌を出している画像です。
この場合は、先ほど発見したファイルのそれぞれについて、ツール analyze_image を適用して、画像ファイルの内容をテキストで記述しています。
手書きメッセージの画像 handwritten.jpg が気になるので、内容を確認してみましょう。
query = '''
手書きのメッセージの画像を表示して。
なんて書いてあるか教えて。
'''
_ = await client.stream(query)
[出力結果]
[image_manager_agent]
手書きのメッセージの画像を表示し、内容をお伝えします。
## Displayed image [1] ##
[image_manager_agent]
画像に書かれている内容は以下の通りです。
This is a handwritten message
to use with Google Cloud
Platform, To demonstrate the capabilities
of the Cloud Vision API to detect
handwritten text,

入力テキストではファイル名 handwritten.jpg は明示しませんでしたが、これまでの会話の流れから正しいファイル名を認識して、内容を読み取ってくれました。
応用的な活用例
ここからは、用意したツールにこだわらず、さまざまな依頼をしてみましょう。次の例はどうでしょうか?
query = '''
子供が喜ぶキュートな写真はどれかな?
2つ選んで表示して、それぞれにキュートなタイトルを付けて。
'''
_ = await client.stream(query)
[出力結果]
[image_manager_agent]
子供が喜ぶキュートな画像を2つ選び、キュートなタイトルを付けて表示します。puppies.jpg と duck_and_truck.jpg が子供に喜ばれると考えられます。
**わんこパラダイス**
## Displayed image [1] ##
**あひるとトラックのおもちゃ箱**
## Displayed image [2] ##


「子供が喜ぶキュートな写真」という、判断基準があいまいな依頼もこなしてくれました。
写真画像とイラスト画像の識別はできるでしょうか?
query = '''
イラスト画像をすべて表示してください。
'''
_ = await client.stream(query)
[出力結果]
[image_manager_agent]
イラスト画像をすべて表示します。対象となるのは、jitensya_papa_3nin2.png と jitensya_papa_3nin_dendo.png です。
## Displayed image [1] ##
## Displayed image [2] ##


うまくいきました! これらを使って、間違い探しをしてみましょう。
query = '''
間違い探しです。先ほどの2つの画像にはどのような違いがありますか?
一言でどうぞ!
'''
_ = await client.stream(query)
[出力結果]
[image_manager_agent]
自転車が電動かどうかです。
これもうまくいきましたが、どうやって電動自転車だとわかったのでしょうか? ファイル名に含まれている dendo で判断している可能性はないでしょうか?
query = '''
なぜ電動自転車だとわかるのですか?
'''
_ = await client.stream(query)
[出力結果]
[image_manager_agent]
画像を分析して理由を説明します。
[image_manager_agent]
バッテリーパックとペダルの近くにある電気記号で電動自転車だと判断できます。
確かに、よく見るとバッテリーパックが描かれています。最後に、少し無茶振りをしてみましょう。
query = '''
この2つのイラスト画像を使った2コマ漫画を作ります。
1つのコマは、1つの画像とそれに付随するメッセージで構成されます。
2つのコマを連続して読むことで、笑えるストーリーになります。
出来上がったら、画像とメッセージを組み合わせた2コマ漫画として表示してください。
'''
_ = await client.stream(query)
[出力結果]
[image_manager_agent]
面白い2コマ漫画を作成します。
最初のコマ:
## Displayed image [1] ##
メッセージ:
「パパ、今日も公園まで競争だ!負けないぞ!」
2番目のコマ:
## Displayed image [2] ##
メッセージ:
「へへっ、実は今日から電動アシスト自転車なんだ!楽勝!」
...(出力画像は省略)...
「画像とメッセージを組み合わせた 2 コマ漫画」を指示通りに生成しましたが、内容が面白いかは微妙なところです。2 コマ漫画を生成するツールは用意されていないので、漫画のストーリーはエージェント自身が考えていると想像されます。もっと面白いストーリーを生成したいのであれば、「笑い」に特化したサブエージェントを用意して、より面白いストーリーが生成できるようにインストラクションを作り込むとよいかもしれません。
まとめ
この記事では、ストレージバケットに保存した画像ファイルを分析する「メディアエージェント」を作りました。ただし、ADK のエージェントでマルチメディアを扱う方法を紹介するのが目的の簡易的な実装ですので、バケット内のファイル数が膨大になると、次のような使い方は難しくなります。
- すべてのファイルの説明文をまとめて生成する
- すべてのファイルの中からイラスト画像を検索する
あるいは、画像ファイルの代わりに動画ファイルを扱う場合は、個々の分析にかかる時間が長くなる恐れもあります。ファイルの検索機能を外部システムとして用意する、動画ファイルの内容を事前に抽出したメタデータを用意するなど、これらの課題に対応する方法はいろいろ考えられますが、まずは、ユーザーに提供するべき機能、そして、ユーザーがどのような手順でその機能を使うのかという点を明らかにすることが大切です。
エージェントの開発と言っても、ユーザージャーニーを定義して、ユーザーに提供する機能をタスクに分解する、それぞれのタスクを実行するツールを実装するなど、基本的な考え方は、一般的なアプリケーション開発と変わりありません。これからエージェントの開発に関わる方は、この機会にシステム設計やアプリケーションアーキテクチャーの考え方を学び直すのはいかがでしょうか。 エージェント開発に役立つ新たな気づきがきっと得られるでしょう。
Views: 0

{kind=link}