

- Cursorで要件定義がエラいスムーズになった話
- (続)Cursorで「詳細設計→ガントチャート草稿」作成がめっちゃ楽になった話
- 「Cursor」×「A5:SQL Mk-2」でテーブル定義書をリッチにする ←本稿こちら
- 「Cursor」×「Obsidian」内部リンク生成&最適化プロンプト
Cursor周りでこすり倒してる感じがしてきていますが、最近は日々トライアンドエラーの頻度も増してきていまして、わずかばかりでも需要があるなら、どんどんと発信していこうという所存です。
序章 ― 私たちは、なぜ “定義書” を信じきれないのか
テーブル定義書――それは一度書いたら「もう安心だ」と思い込みやすいドキュメントです。しかし、私の組織でも何度となく “実装と定義書の乖離” に悩まされてきました。
仕様変更の影響範囲が読めない。
リファクタ後のカラムが何のためにあるのかわからない。
属人化した SQL がレビューをすり抜ける……
そうした “静的な紙の設計書” と “動的に変わるコードベース” のギャップを埋める――それが今回紹介するフローの出発点でした。
「A5:SQL Mk-2」について
結構昔から、テーブル定義書を定義するのにたびたび使っていたツールでしたが、
Excelで出してメンテナンスが後後しづらい な、とか、
DBスキーマから参照できる情報だといまいち足りない んだよな、みたいな悩みがあっていまいち使いきれてなかったんですよね。
そこに来て 「Cursorの登場」 と、今まで「誰が使うねん」と思っていた 「md形式のテーブル定義書」が見事にマリアージュ してしまったという感覚です。
背景 ― 「A5:SQL Mk-2 × Cursor」で狙ったこと
-
1.A5:SQL Mk-2 で “Markdown形式のテーブル定義書” を一括生成
-
2.Cursor を使い、
- 各カラムが どの Controller/Model/Job で更新・参照されているか
- JOIN 先やユースケースがどこに潜んでいるか
を自動抽出させる
-
3.“構造” と “使われ方” を一つの
.mdに同居させる
結果、レビュー効率 はもちろん、オンボーディング時の「とっかかり資料」としても強力になりました。
「テーブル定義書は“スキーマのスナップショット”ではなく、
“振る舞いを語るストーリーブック” に変えられるのだ――」
そう実感できたのが、この取り組みの最大の収穫です。
全体俯瞰 ― まずは 4 行で流れを掴む
- A5:SQL Mk-2 で “テーブル定義書” の Markdown を吐き出す
- 定義書とソースをワークスペースへ
- Cursor で Prompt-1 を叩き、コード横断検索 → 追記案を生成
- その場でレビューし、OK なら Prompt-2 で 元ファイルを直接書き換え
- 差分を Git で管理し、PR で軽量レビュー
手順
1. A5:SQL Mk-2 で “テーブル定義書” の Markdown を吐き出す
1-① メニューから「テーブル定義書作成」を選択
メニューバーから
データベース(D) → テーブル定義書作成(S)...
をクリック
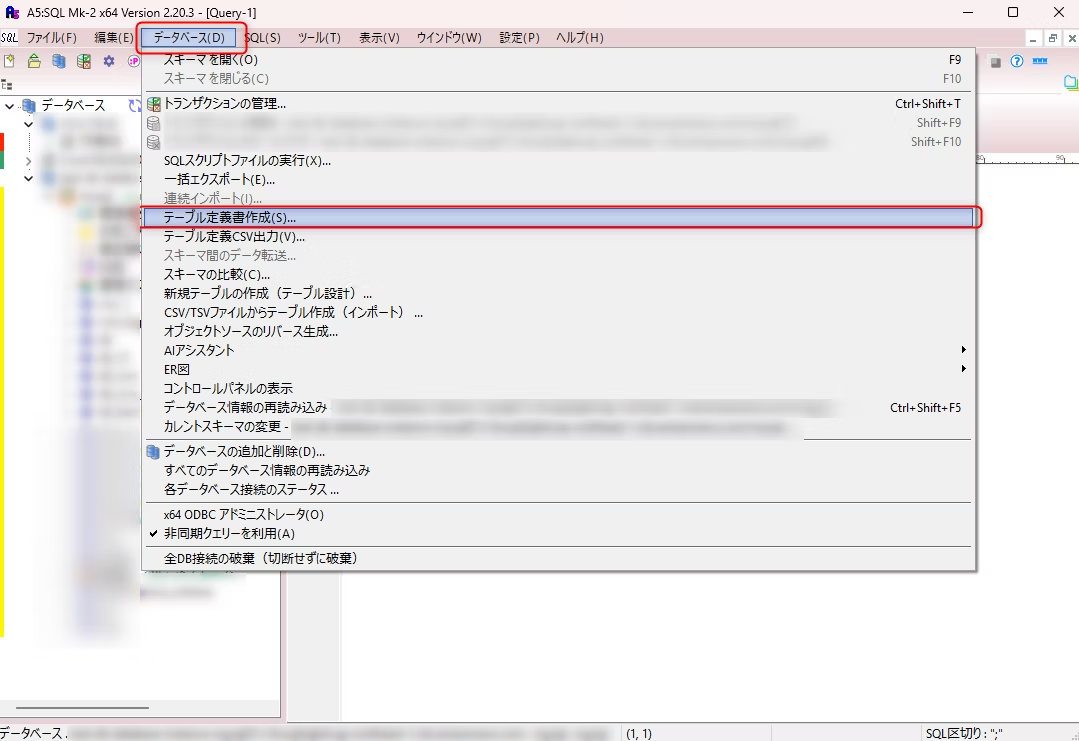
1-② テーブル定義書作成ウィンドウの設定
「テーブル定義書作成」ウィンドウが開いたら、以下を設定:
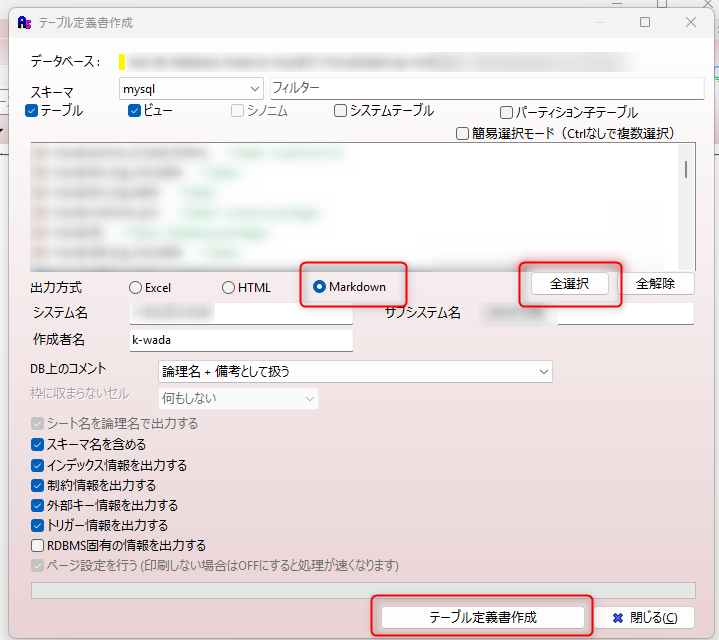
1-③ テーブル定義書を出力
画面右下の テーブル定義書作成 ボタンを押下
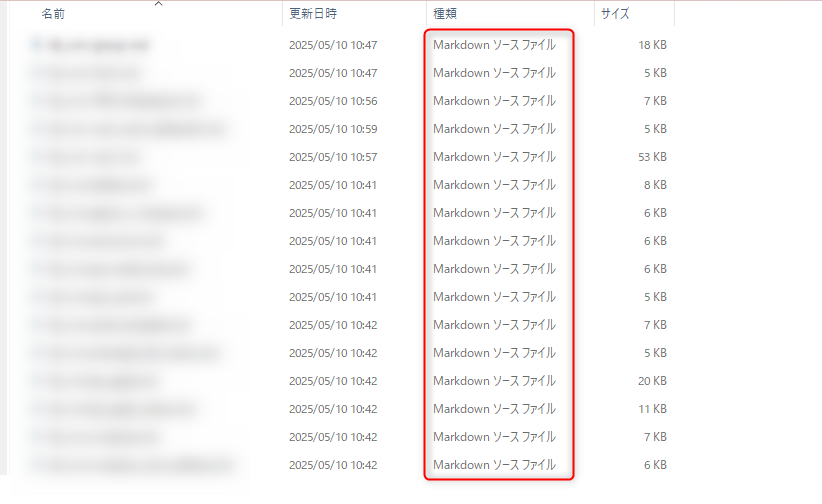
→ テーブルごとの Markdown ファイルが生成される!!!
2. 定義書とソースをワークスペースへ
2-1. 「Add Folder To WorkSpace …」で、ソースコードプロジェクトに、テーブル定義定義書フォルダを追加
2-2. Cursor 左側ペインの “+” をクリック
2-3. テーブル定義書ファイル と 処理してそうなソースコードディレクトリ を ドラッグ&ドロップ
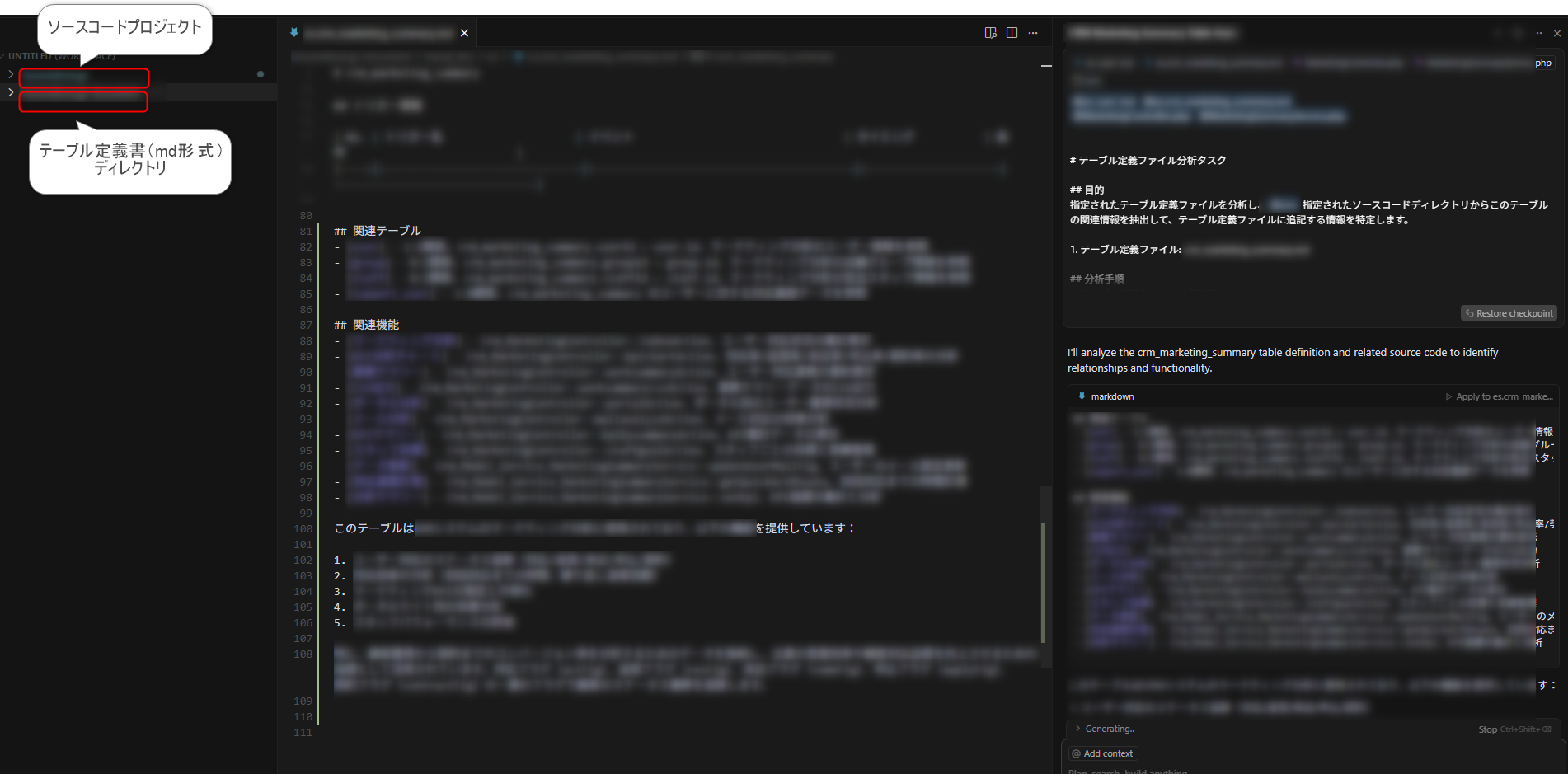
3. Prompt-1 ― 分析フェーズ の実行
以下のプロンプトを張り付け→実行。
# テーブル定義ファイル分析タスク
## 目的
指定されたテーブル定義ファイルを分析し、指定ソースコードから関連情報を抽出して、
「更新条件」「登録値の定義」「関連テーブル・カラム」を列挙する。
## インプット
* テーブル定義ファイル: /docs/schema/sample_table1.md
* ソースコードディレクトリ: /app, /database/migrations
## アウトプット
- Markdown 形式の追記用断片
- カラムごとに以下を記述
* 更新条件: どのユースケースで値が変わるか
* 登録値の定義: デフォルト、NOT NULL 制約、アプリ側バリデーション
* 関連カラム: 外部キー・JOIN 元など
**制約**
- コードコメント≠真実の場合を想定し、実装ロジックを優先
- 推測した場合は〈Assumed〉タグを付与
- 30〜60 秒ほどで 「## 関連テーブル」「## 関連機能」「###
」 という塊が返ってきます - もし 誤検知(例えば “LIKE 検索” を UPDATE と誤解する など)があれば、“その場で追質問” して再生成させるのがコツです
4. Prompt-2 ― 更新フェーズ へシームレス遷移
続けて同じチャットに貼り付け。
# テーブル定義書更新タスク
## タスク
- 「sample_table1.md」に、解析結果をセクション単位で追記する。
- "## カラム情報" は対応するカラム行へ追記
## 追記内容
| カラム名 | 更新条件 | 登録値の定義 | 関連テーブル・カラム |
|---------|---------|-------------|---------------------|
| ... | ... | ... | ... |
**ルール**
- 既存記述は改変せず、追記のみ
- Markdown テーブルとして整合すること
- Yes/No を返すだけでなく、Cursor 側で “直接ファイルを書き換え” ます*
5. Git へコミット
(ドキュメント管理をgit管理していたりする場合は、こちらもぜひ)
私が感じた効能 ― “言葉” と “行動” の距離が縮まる
- 「何のためのカラムか?」 が コード片 とともに残る
- スキーマ変更 PR で “想定外の副作用” を拾いやすくなった
- diff =会話の起点 になるため、レビューが “指摘” から “対話” へシフト
失敗と学び ― AI まかせにしない 3 つの約束
失敗例: JOIN 先を誤認し、不要な外部キーをドキュメントに追記してしまった。
原因は “LIKE ‘%address_id%’” を安易に拾ったことでした。
そこで、私は次の 3 点を必ず守るようにしています。
- “○○Controller@△△” の メソッド単位 で必ず人間が目を通す
- 「更新条件」≠“頻出 UPDATE 文” であることを自覚する
- AI が出した “関連テーブル” を ER 図でクロスチェック する
これらは 「AI を盲信しない安全弁」 として機能しています。
結び ― “ドキュメントは静的” という思い込みを壊すために
私はずっと「ドキュメントを書く時間が惜しい」と感じていました。
しかし、“AI で書かせ、人間はレビューに専念する” という構図を手に入れた今、
ドキュメントは “変化の速いコードベースと同じ速度で呼吸する存在” へと変貌しました。
もちろん、これで万能ではありません。
それでも――
「向き合う」 という言葉を、“ひたすら行動で示す” ための一手として、
今回のフローはチームにとって大きな意味を持ったと感じています。
おわり。
Views: 3

{kind=link}