まず、数学者のアラン・チューリングは1950年10月に「計算する機械と知性(Computing Machinery and Intelligence)」と題した論文を発表。この中で「人間の質問者が『相手が機械か人間か分からない状態』において、相手となる機械と会話をし、『人間か機械か判別できない』場合、その機械は『思考』していると言え、『人間的で』であると言える」と記しました。この考えはAIの知能の程度を測定するチューリングテストとして現代まで残っています。

1954年には世界初の高水準言語「Fortran」が登場。

1956年には「人工知能(Artificial Intelligence)」という用語が誕生しました。

人工知能という用語が提唱されたダートマス会議の提案書には「機械に言語を使用させ、抽象化と概念を形成し、今は人間にしか解けない問題を機械が解くこと、そして機械が自分自身を改善する方法を見つける試みが行われるだろう」と記されています。

1967年にはマサチューセッツ工科大学のMAC計画(Project MAC)で作成されたチェスプログラム「Mac Hack VI」がレーテイング1510の強豪チェスプレイヤーに勝利しました。

1997年にはAppleの名を世に知らしめることになった「Apple II」が登場。

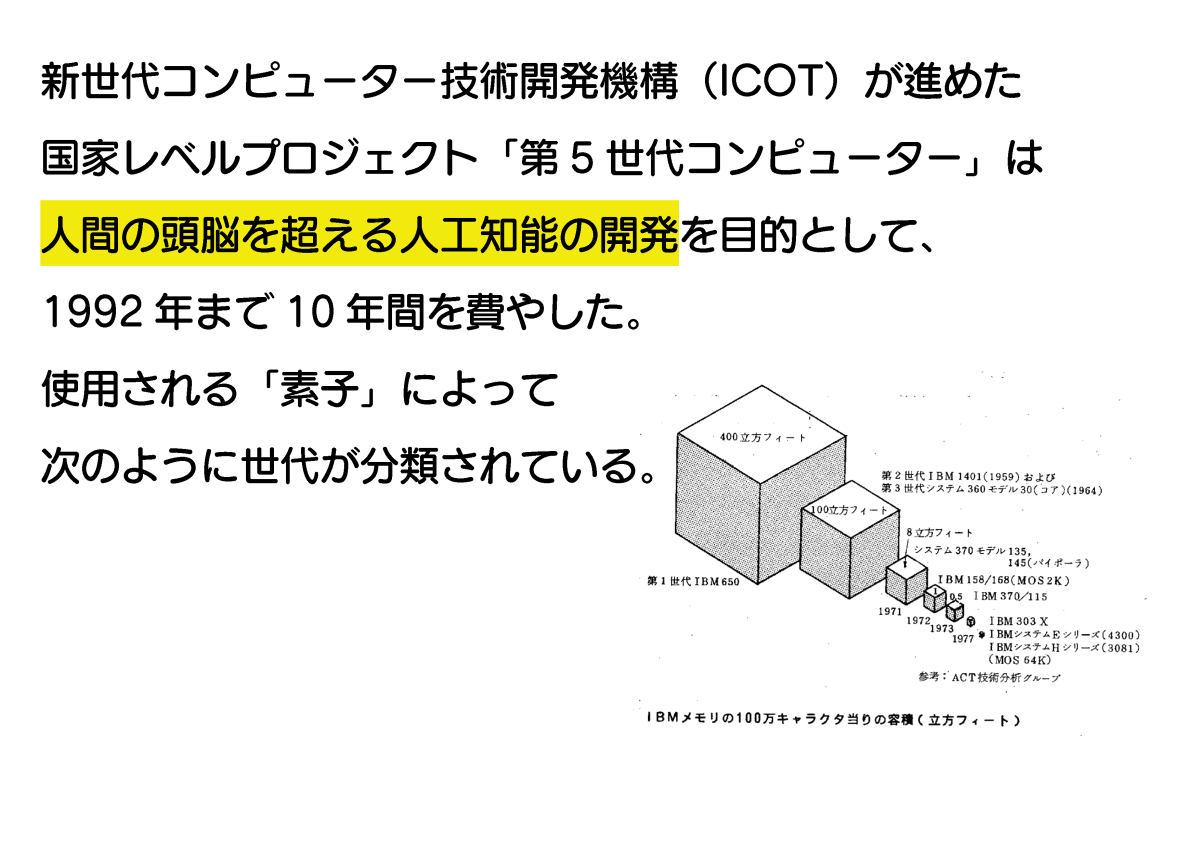
そして、1982年には日本の通商産業省が新世代コンピュータ技術開発機構(ICOT)を設立し、「第5世代コンピュータプロジェクト」を開始しました。

第5世代コンピュータプロジェクトは「人間の頭脳を超える人工知能」の開発を目的としたプロジェクトです。つまり、1982年の時点で日本は超知性の開発プロジェクトを立ち上げていたというわけ。
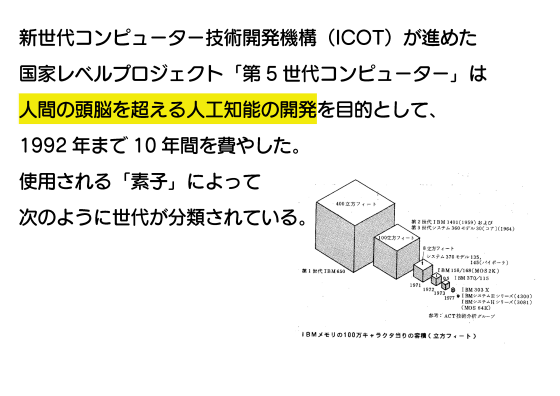
第5世代コンピュータプロジェクトではコンピュータに使用される「素子」ごとに第1世代~第5世代に分類し、「人間の頭脳を超える人工知能」を動作させられる第5世代コンピュータの開発を目指していました。第1世代の回路素子は「真空管」。

第2世代の回路素子は「トランジスタ」。

第3世代は「集積回路(IC)」。この辺りで「オンライン処理」「並行処理」といった処理内容が想定されています。
第3.5世代は「大規模集積回路(LSI)」。

第4世代はLSIをさらに高密度化した「超LSI」で、複数システム間の大量エータ処理を可能とする「ネットワーク」や、大量データの集中管理を可能とする「データベース」の処理が想定されています。ここまでは現代では実現済み。
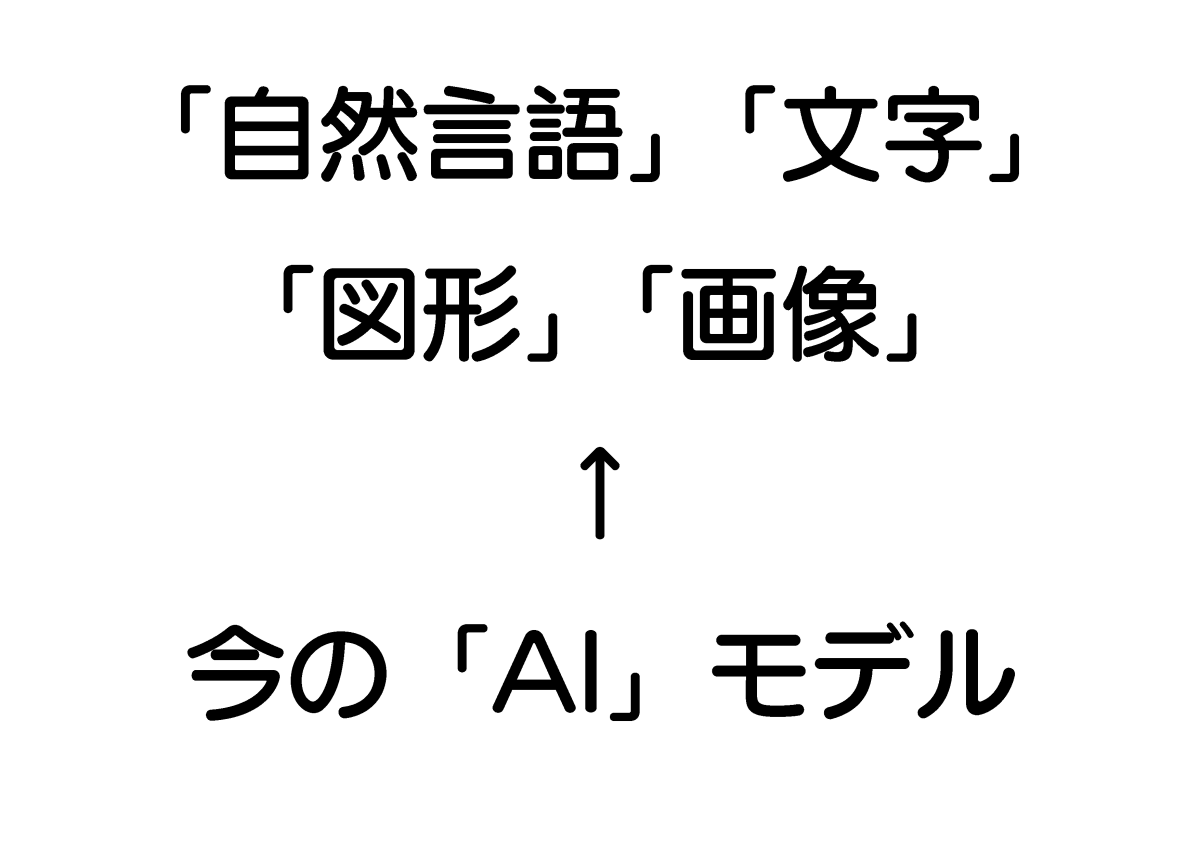
そして問題の第5世代。回路素子は「不明」。記憶素子も「不明」。処理対象として非数値データである「自然言語」「文字」「図形」「画像」が挙げられ、超高速演算処理や超高速記憶検索も可能とされています。

「自然言語」「文字」「図形」「画像」を処理できるものと言うと、まさに現代のマルチモーダルAIモデルが合致します。
つまり、我々はかつて想定されていた「本物の未来」に生きているのだ。
この未来を先取りしてしまったプロジェクトの計画書にはまだ続きがあります。

第5世代コンピュータプロジェクトに要請される機能は大きく分けて4つ。

1つ目は「知能レベルを高め、人間の良き理解者としての親和性を高めること」で、この機能を実現するために自然言語の利用が求められています。

2つ目は「人間の代替をする能力や人間にとっての未知の分野を開拓する場合の支援能力を持つこと。意思決定支援システム。知能を持つロボット」。

3つ目は「各種の形態の情報を必要に応じて簡単に即時入手できること。多形態データベース、高度分散データベース」。

4つ目は「未知の状況をシミュレートすることにより新しい知見を得ること。実験システム、合金合成など」。

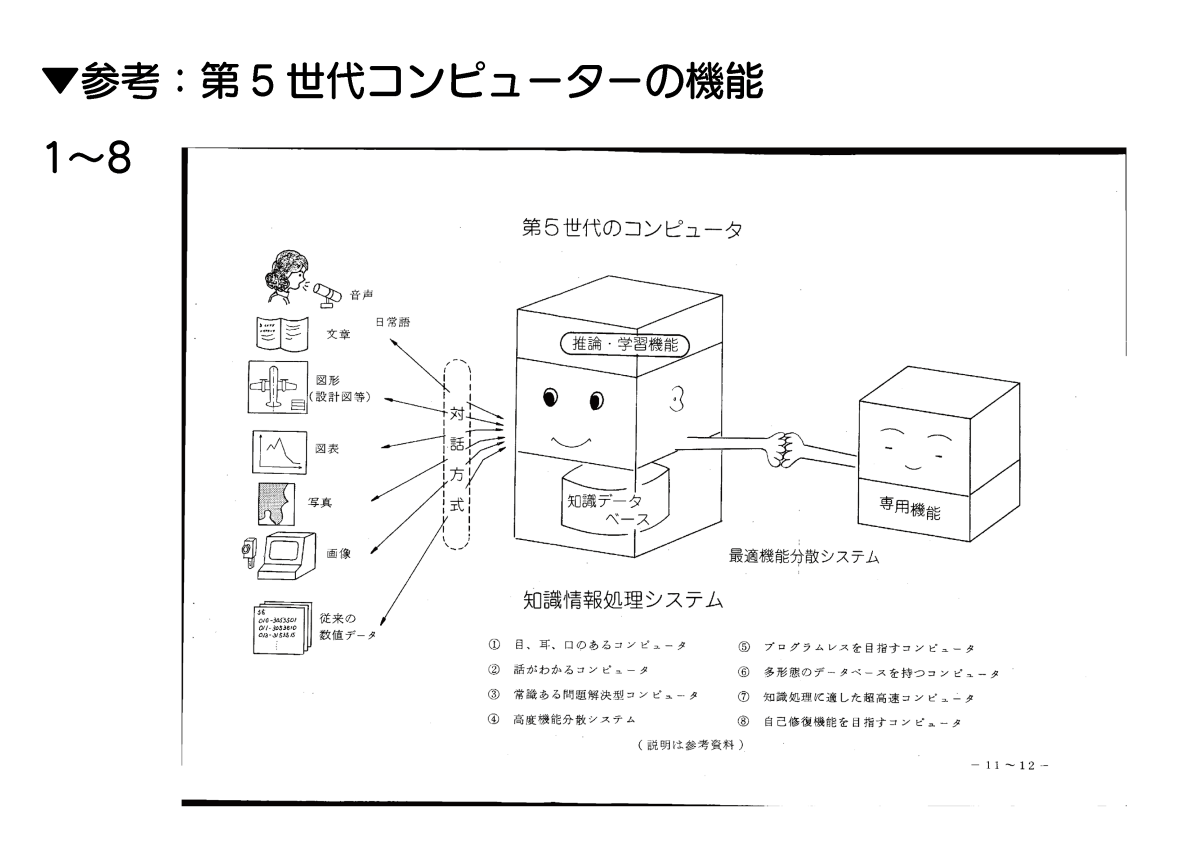
第5世代コンピュータプロジェクトでは未来を先取りした8種類の特徴も想定されていました。
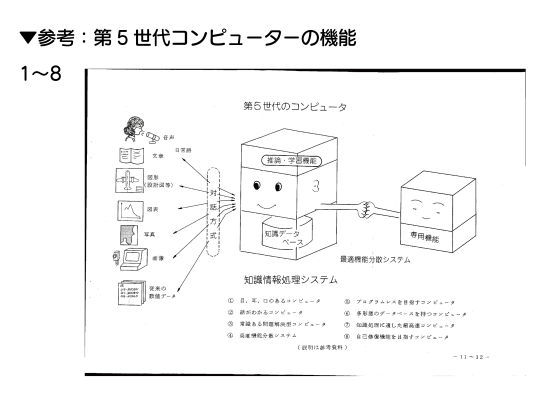
まず1つ目が「人間のように眼・耳・口を備え、音声・図形・文字を直接入力できる」というもの。これはカメラ・マイク・スピーカーで実現されています。

2つ目が「プログラミング言語を知らない人でも、日常語で応対しながら高度な機能を利用できるようになる」というもの。これも完璧とは言えないものの大体実現に成功しています。また、日常語を扱う機能を活用した「自動翻訳および通訳」も想定されていました。

3つ目が「記憶している情報を用いて、未知の問題を推論して解決する」というもの。この「学習した内容を用いて未知の問題を推論する」という技術はここ数年でAI開発者たちがものすごい勢いで発展させています。

4つ目は「『多様化された用途に合わせて最適化されたコンピュータ』を組み合わせて上位システムを構築する」というもの。

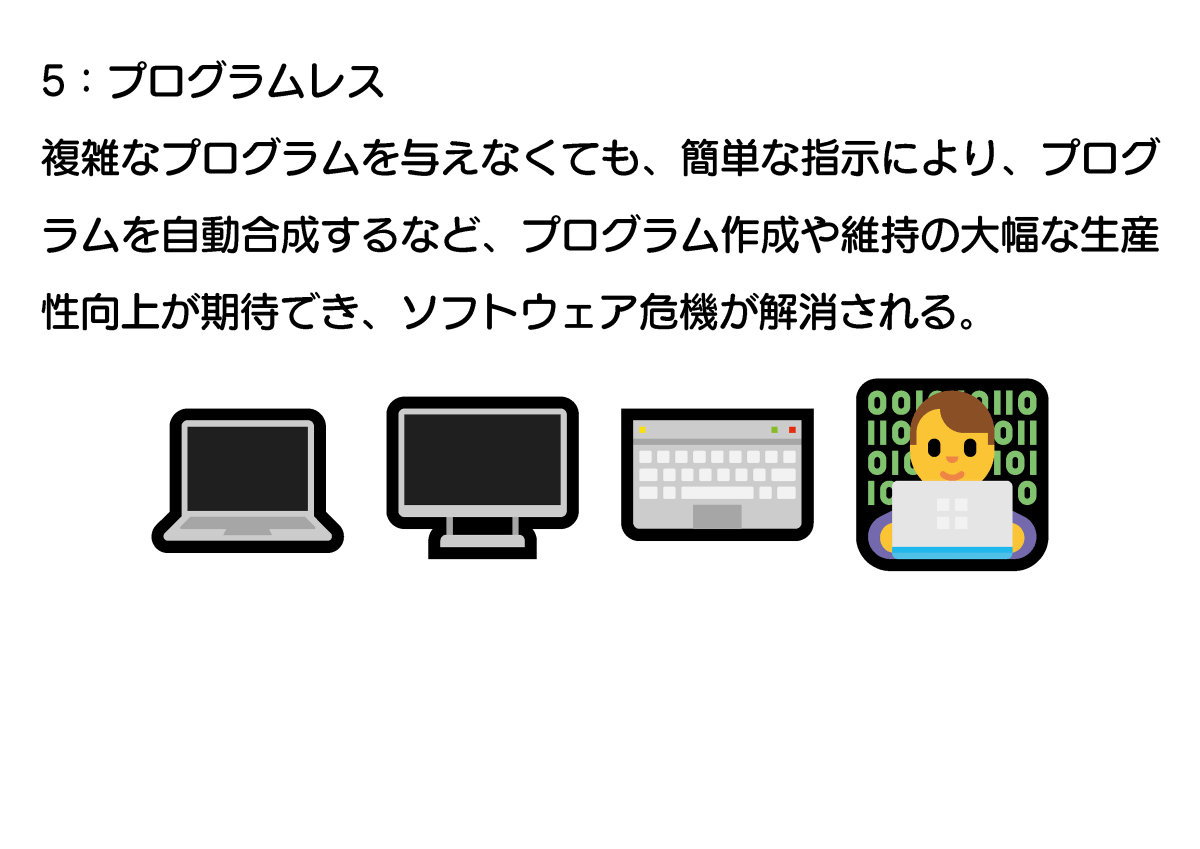
5つ目は「簡単な指示でプログラムを自動合成する」という機能。この機能もAIによって実現されつつあります。
6つ目は「数値情報以外の音声・図形・画像・写真などを整理して記録し、いつでも取り出せる多形態データベース」の実現。

7つ目は「超高速な処理が可能なコンピュータ」です。現在のコンピュータ業界では「いかに大量のデータを並列処理するか」という点が大きな課題になっているわけですが、第5世代コンピュータプロジェクトの時点で「超高速に並列処理を行う技術が必要である」ということが提言されていました。

そして8個目が「高信頼性があり、保守性に優れている。障害に対し、その検出と修復を自動的に行う機構を持つ」というもの。「障害の自動検知と自動修復機能」は今AIに求められている機能とも言えます。
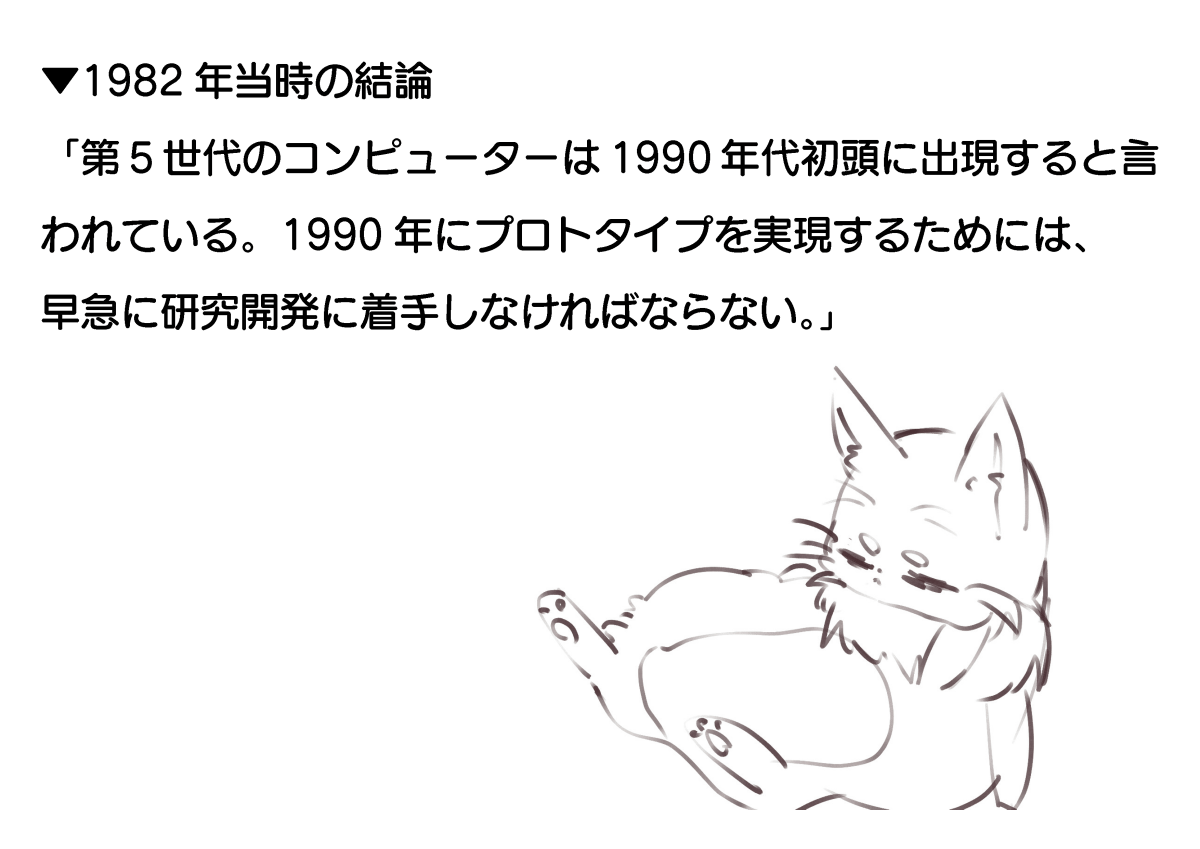
そして、計画書は「第5世代コンピュータは1990年代初頭に出現すると言われている。1990年にプロトタイプを実現するためには、早急に研究開発に着手しなければならない」という結論を導き出しています。しかし、第5世代コンピュータプロジェクトには総額540億円もの国家予算が投じられたものの、超知性を実現することなく1992年に終了しました。
第5世代コンピュータプロジェクトは頓挫しましたが、世界のコンピュータ技術は着実に進歩を続けました。

1995年にはWindows 95が登場。

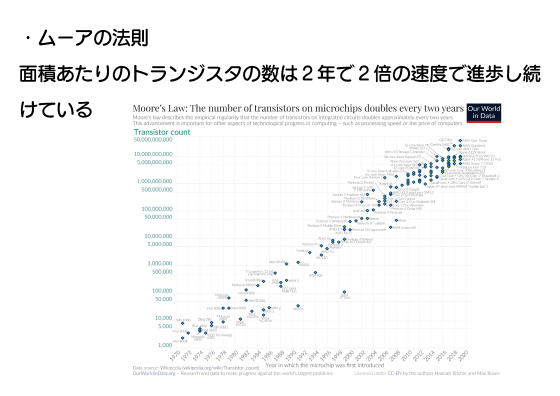
「半導体の面積当たりのトランジスタ数は2年ごとに2倍になる」というムーアの法則に沿ってプロセッサの微細化も進みました。
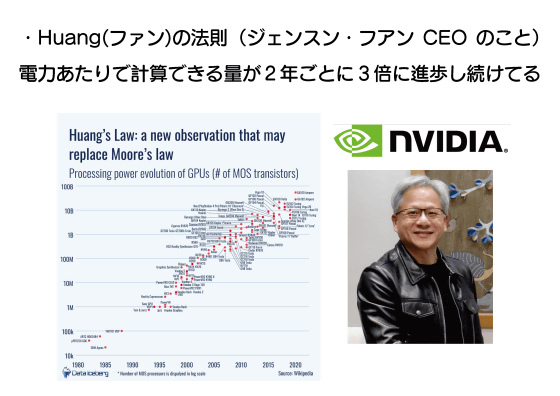
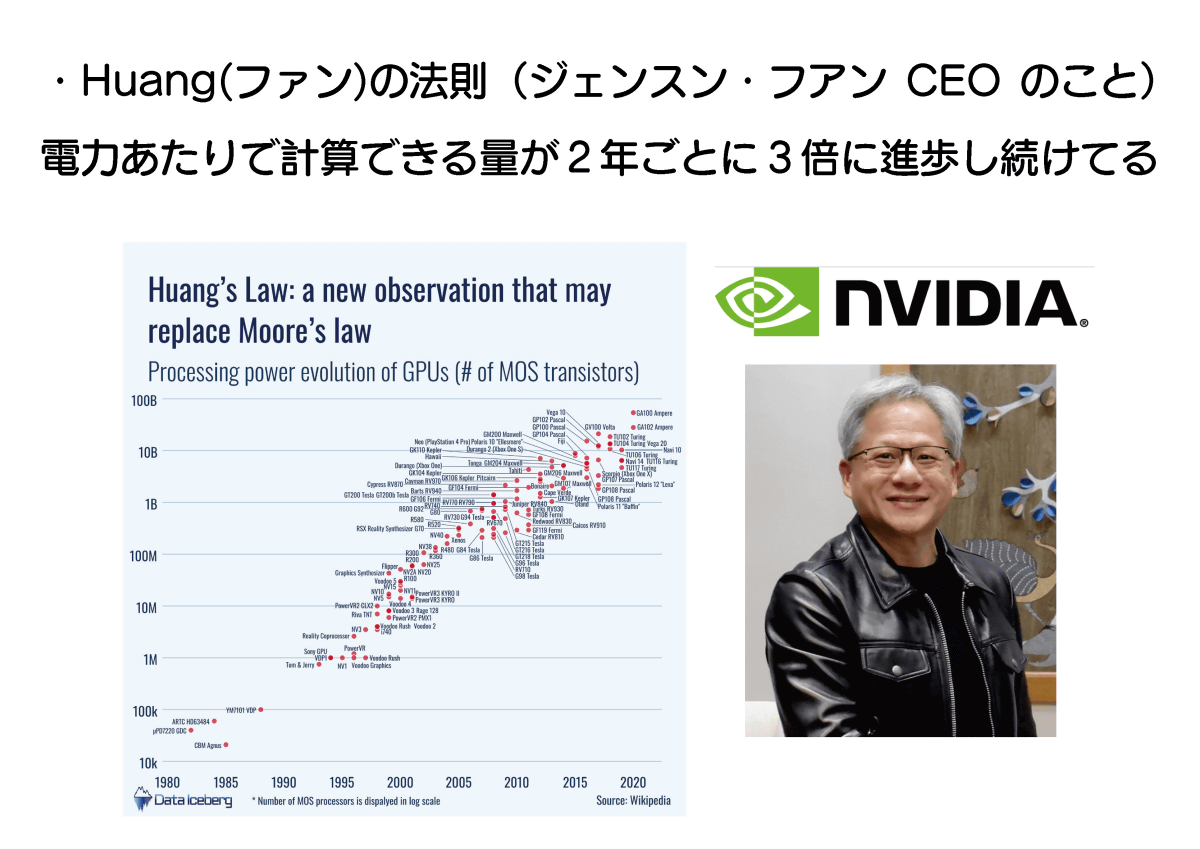
ちなみに、最近では「電力当たりの計算可能量が2年ごとに3倍になる」という「ファンの法則」も提唱されています。ファンはNVIDIAのジェンスン・フアンCEOのこと。
2004年頃にはブログブームが到来。インターネット上に大量のデータが出現しました。
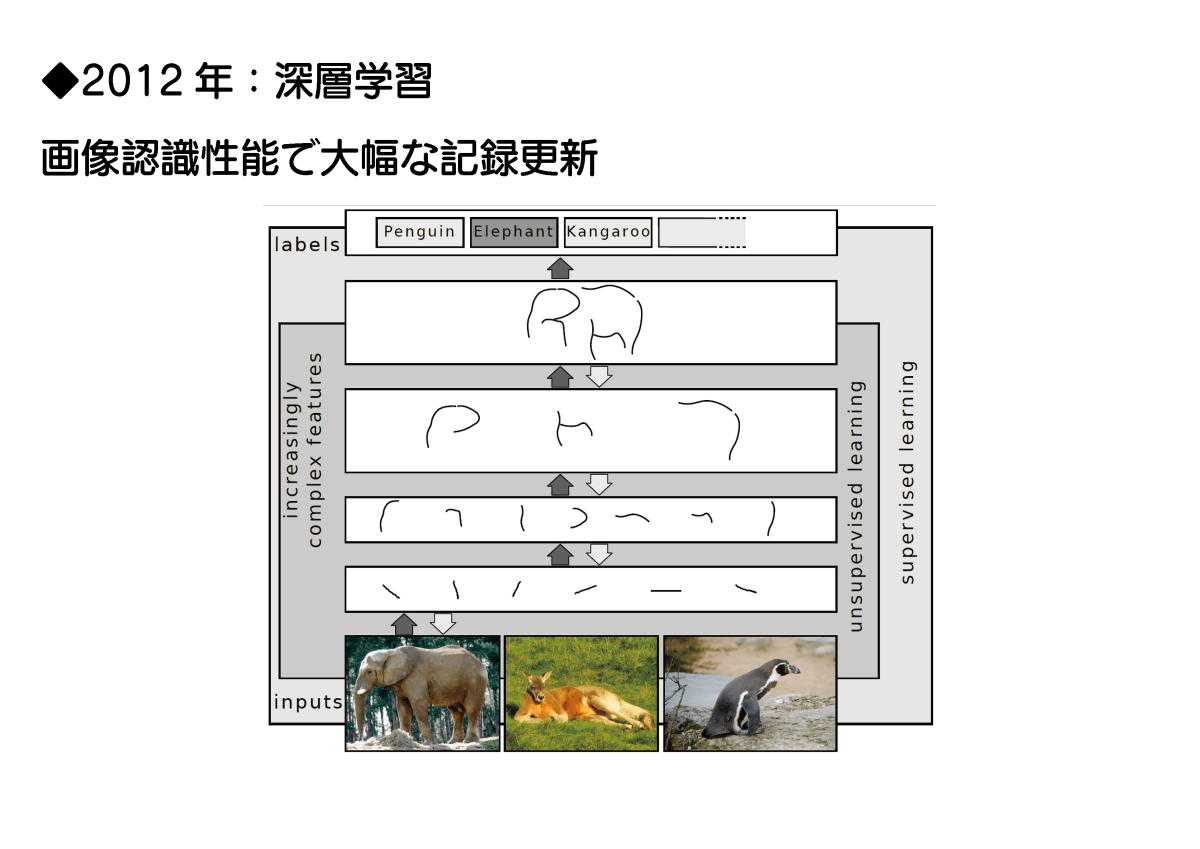
2006年には脳を模倣した計算手法「ニューラルネットワーク」を用いた機械学習モデル「深層学習(ディープラーニング)」が発明されました。ディープラーニングは2012年に高精度な画像認識技術「AlexNet」が登場したことで一気に注目を集めるようになります。
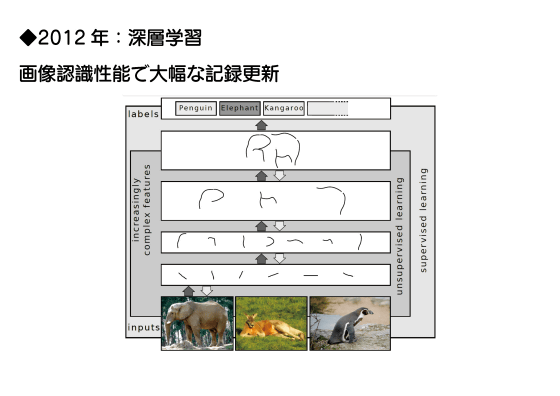
その後、ニューラルネットワークの大規模化がどんどん進みました。

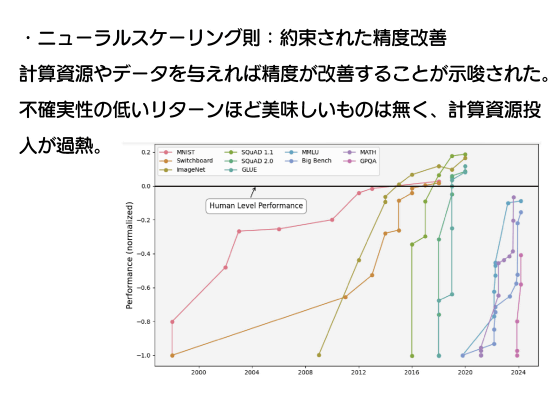
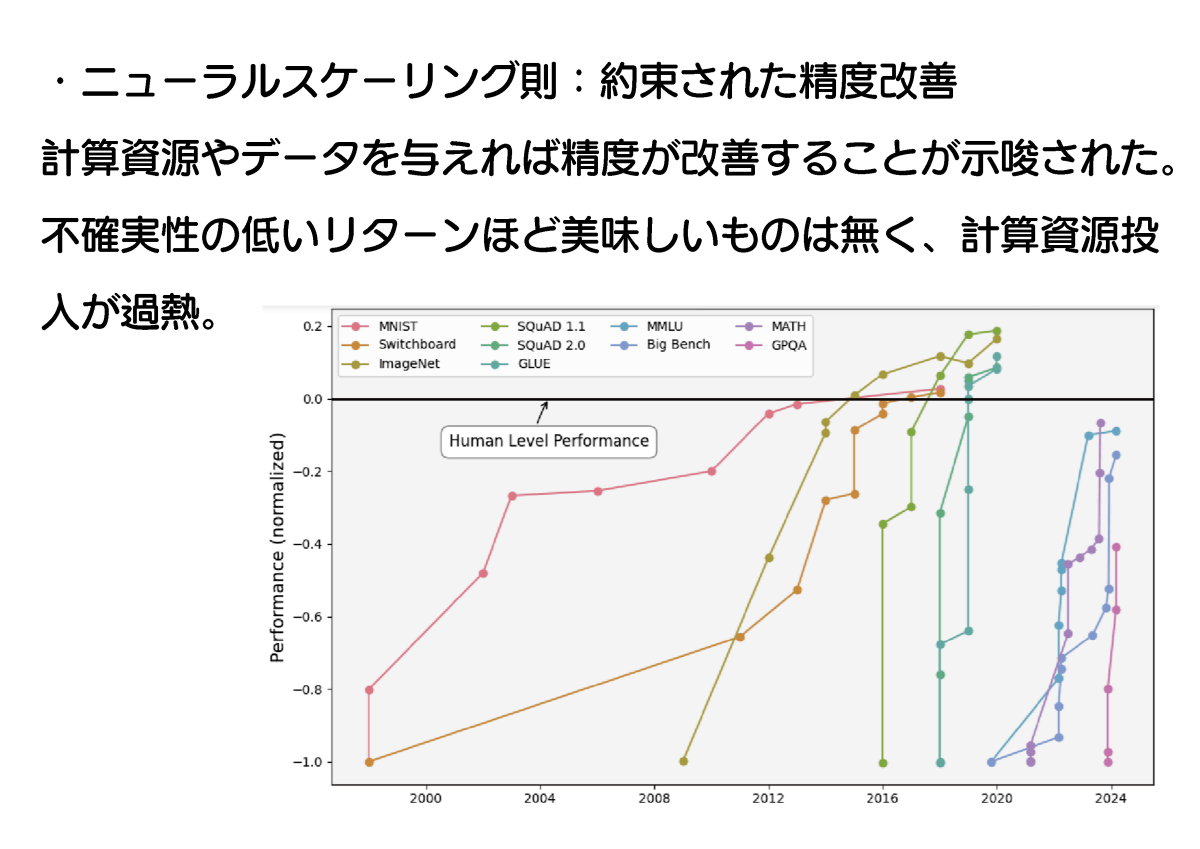
2020年にはOpenAIが「スケーリング則」を提唱しました。これは「AIモデルの性能は、『学習に使われるデータの規模』『学習に使われる計算量』『モデルのパラメーター数』が増加するほど強化される」というもので、平たく言えば「AIの性能は開発にコストをかけるほど上昇する」ということを示したというわけ。これによりAI開発は「不確実性の低いリターンを得られる分野」と見なされ、計算資源の投入が過熱しました。
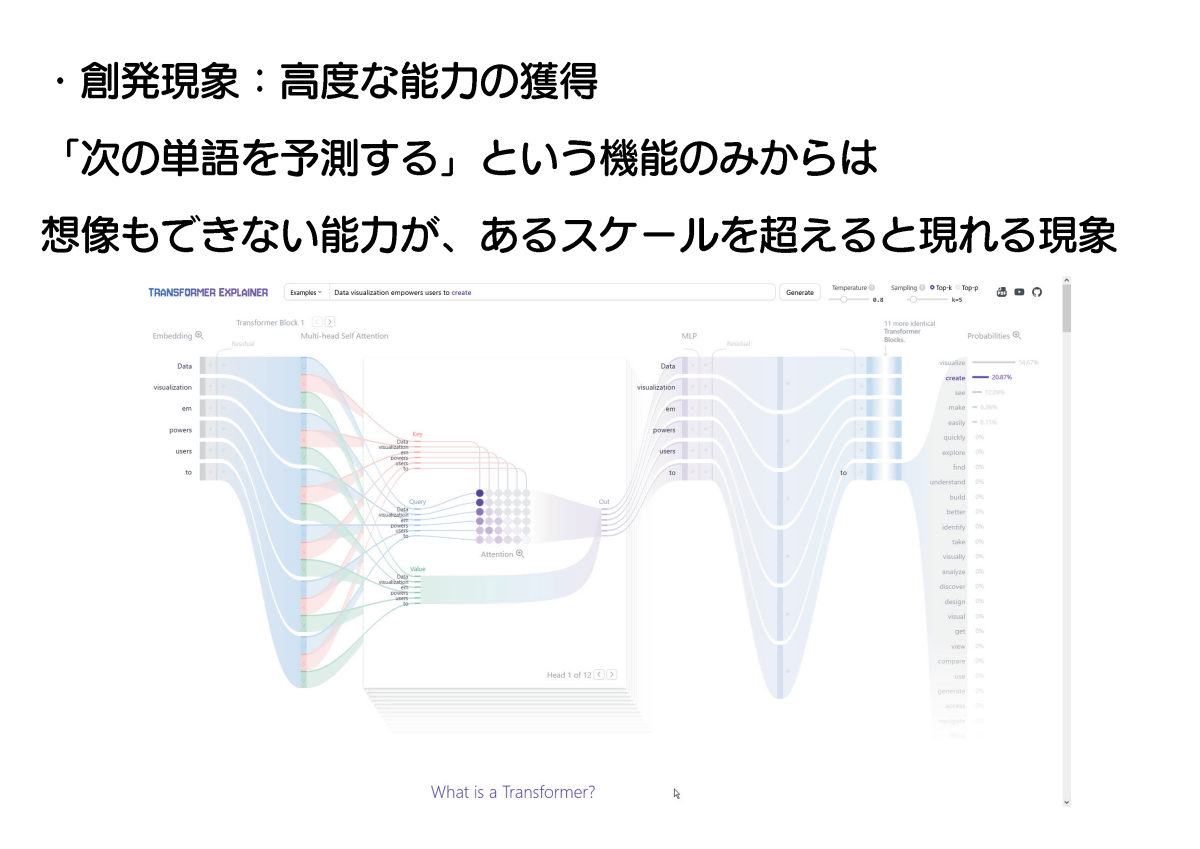
初期の言語モデルは「次の単語を予測する」という単純な機能を持ったものでしたが、学習させるデータを増やしていった結果、ある時点でGPT-3などの「『次の単語を予測する』という機能だけでは説明できない、知能のようなものを持ったモデル」が生み出されました。この「ある要素が大量に集まった際に、単体では実現不可能な現象が発生する効果」は「創発」と呼ばれています。
GPT-3のようなモデルは「学習時に知らなかった物について想像できる常識力」を獲得しているとも言えます。

そして、2022年にはChatGPTが登場しました。ChatGPTはリリースから1週間以内に100万ユーザーを突破し、Googleがコードレッドを宣言する事態にまで発展しました。それほどの破壊的出来事だっというわけ。

その後もAIモデルのモデルサイズはどんどん増加していき、それに伴って性能も向上しました。2023年12月にはGoogleがGeminiをリリース。Geminiは複数のテストで人間の専門家を超えるスコアを記録しました。
自動運転の世界でもAIが活用されるようになりました。これまでの自動運転技術はアルゴリズムベースだったのですが、2019年には自動運転技術を開発するWayveがAIを用いた自動運転車のデモ走行に成功しています。

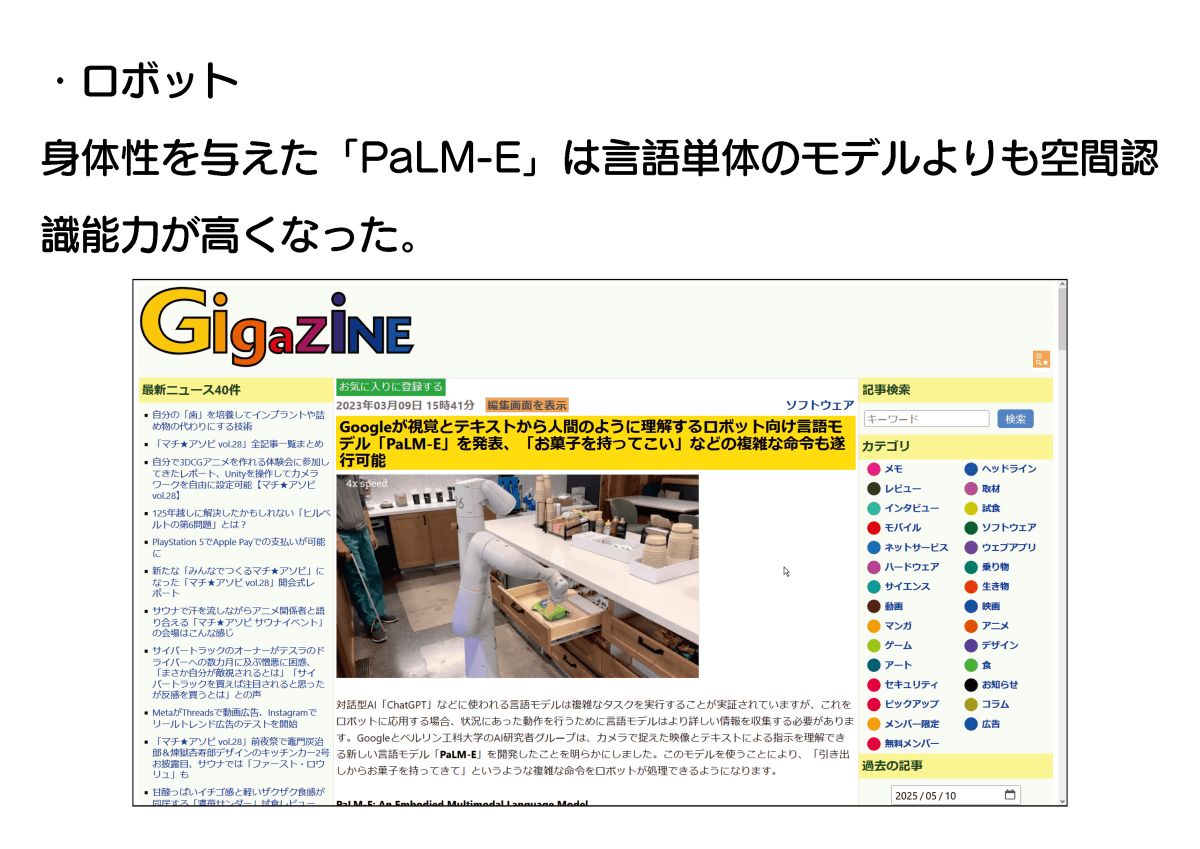
さらに、ロボットにもAIモデルが搭載されるようになりました。2023年3月にはGoogleがロボット向け言語モデル「PaLM-E」を発表しています。
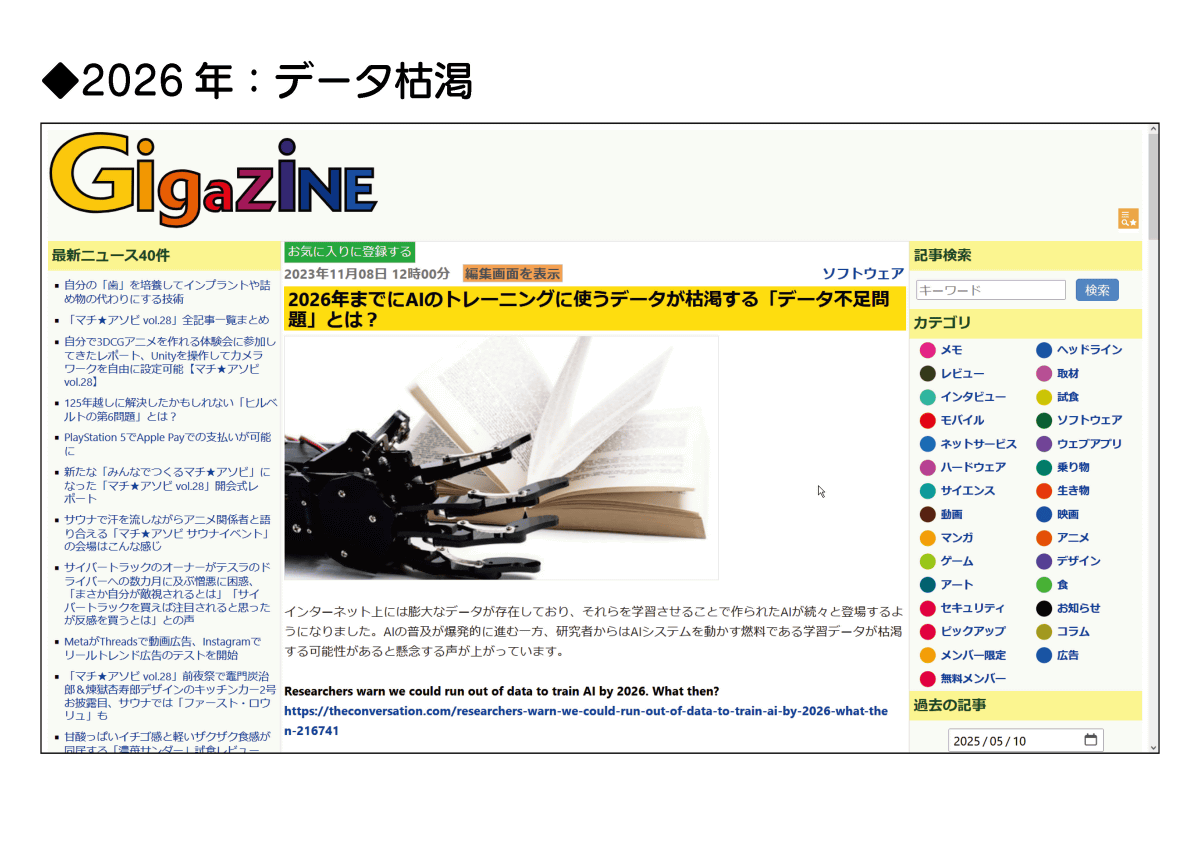
ここからは未来の話。AIモデルは学習データを増やすことで性能を向上させてきたわけですが、学習データは2026年には枯渇すると予測されています。

ちなみに、データ容量を人間にも分かりやすく示すとこんな感じ。人間が一生で話す言葉の総量は2GBとされています。また、電子書籍プラットフォーム「Kindle」のライブラリには2TB、Googleの書籍全文データベース「Googleブックス」には10TBものデータが蓄積されています。さらに、アメリカ議会図書館には国内外問わずありとあらゆる書籍や資料が保管されており、総データ量は30TBになると見積もられています。仮にアメリカ議会図書館の全データを学習したAIが登場したとすると、とんでもない性能になりそうです。

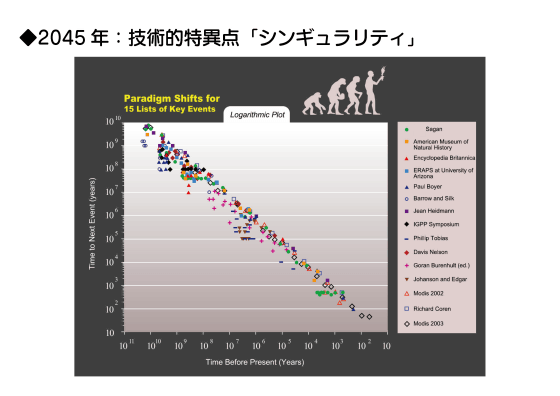
そして、2045年にはAIが人間の知能を超える「シンギュラリティ」が発生すると言われています。
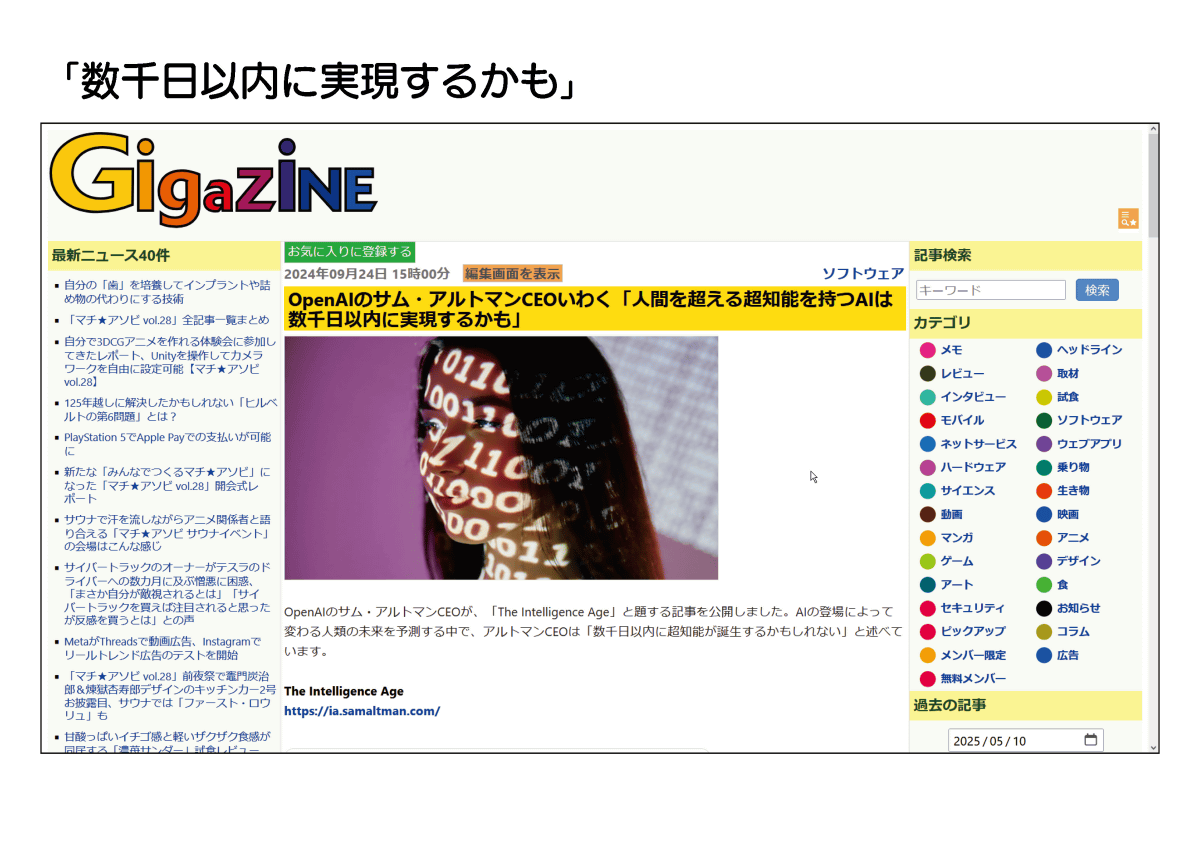
冒頭に述べた通り、アルトマンCEOは「超知性は数千日以内に実現するかも」と予言。
あと26年と数カ月以内に超知性が登場するということですが、現状のAIは「質問に対して完全に間違った回答を返してくる」とか、「画像を生成するように頼んでも指示とまったく異なる画像を出力する」といったようになかなかのポンコツぶりを発揮しており、超知性にはほど遠いように見えます。

どうしてAIがちょっとポンコツなのかというと、人間のように「現実」の出来事を実感を伴って学習することができないから。
データの枯渇を乗り越え、人間のような体を持たないAIに「現実」を教え込み、超知性に至らしめる方法は2つ考えられます。

まず1つ目は、地球とまったく同じ物理状態や環境を備えた「セカンドアース」を電脳空間に作成し、セカンドアースにAIを解き放って学習させるということ。セカンドアースは理論上何個でも作り出せるほか、現実世界と違って時間を早送りすることもできるため、短時間で人生数千億周分の学習をさせられるというわけです。このアイデアの実現を目指して複数の研究機関や企業が研究開発に取り組んでおり、すでにカーネギーメロン大学の研究チームが現実世界の43万倍の速度でロボットを訓練できる物理エンジン「Genesis」を公開しています。

さらに、セカンドアースで学習して得た技能を現実世界で発揮するために、AIを受肉させるロボットも必要です。
今のAIは「人間による入力を待ち、入力に対して応答する」という仕組みです。しかし、超知性には人間による入力がなくとも思考できる自律性が求められます。つまり、次の一歩は人間による問いかけがなくとも行動できるAIの開発というわけ。
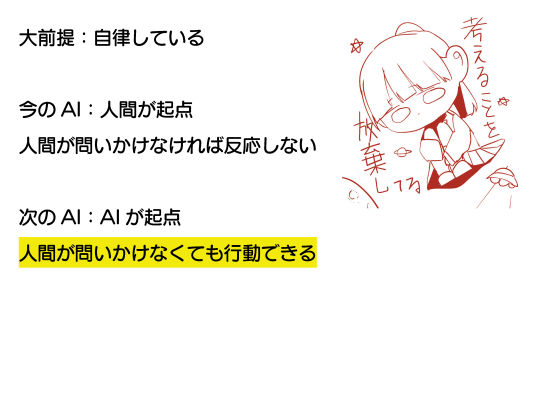
セカンドアースでの学習や肉体となるロボットの開発を経て、AIは超知性へと至り、自律的な創作を始めるというわけです。

チャットAIの登場によってAIが一気に身近なものとなりました。ちょっと大人になってしまった我々にはAI普及以前のワークフローや考え方が染みついていてAIありきの世界になかなか慣れられないわけですが、次世代の主役たる子どもたちのAIへの順応性はかなり高く、編集長の観測範囲でも「絵の描き方を学びたい子どもが、自分で描いたイラストをお絵かきAIに入力し、理想のお手本を出力し、模写を繰り返したことで、AI出力の絵を修正するために必要なスキルがメキメキ向上」といった事例が見られています。それでも、AIとのやり取りはリスクを伴うため、AIの使い方や関わり方を子どもたちに教える場を作ることも重要です。

しかし、「ITリテラシー教室」のような子どもにとって面白くない内容だと、なかなか興味を持ってもらえません。
GIGAZINE的には、イラストを描いたり小説を執筆したりといった創作活動を通してAIに触れられる「創作部」のようなものがAIリテラシーの向上にも適していると考えています。

というわけで講演はおしまい。

現地ではこのあと質疑応答があり、「今のところ、AIの利用はイラストやコーディングなどのクリエイティブな分野で活用されているけど、人間の代わりに単純労働してくれるAIはまだなのか」といった質問も飛び出しました。今後のマチ★アソビでもGIGAZINEのオフライン講演会を実施予定なので、来てください~。楽しいよ。












































{kind=link}