2025年6月18日、テクノロジーの進歩にもかかわらず、最新の大規模言語モデル(LLM)が難易度の高いコーディング問題において人間の熟練プログラマーには太刀打ちできないことが明らかになりました。具体的には、競技プログラミングの分野でのパフォーマンスを評価する「LiveCodeBench Pro」という新たなベンチマークが導入されました。このベンチマークは、国際的な競技プログラミングイベントの問題を基に作成されており、持続的な更新が予定されています。
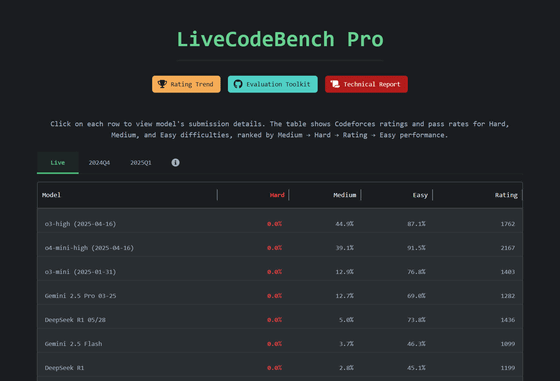
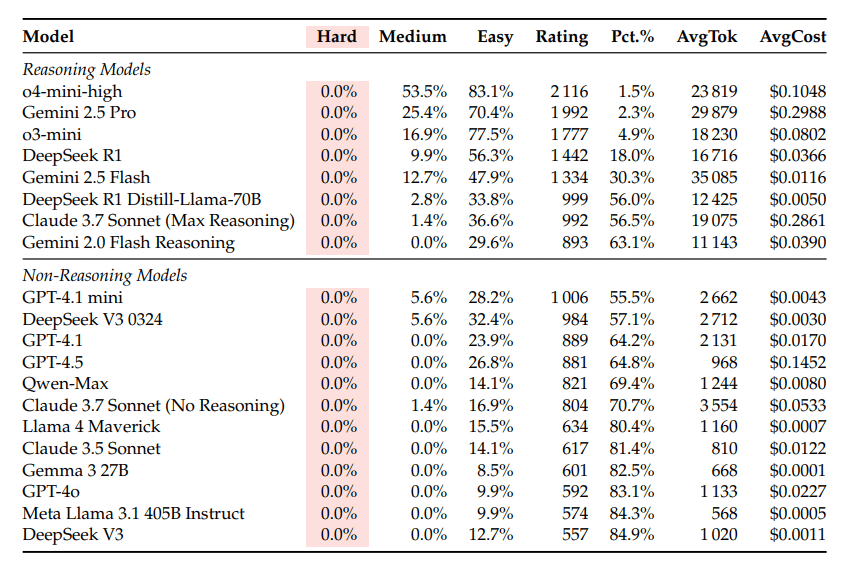
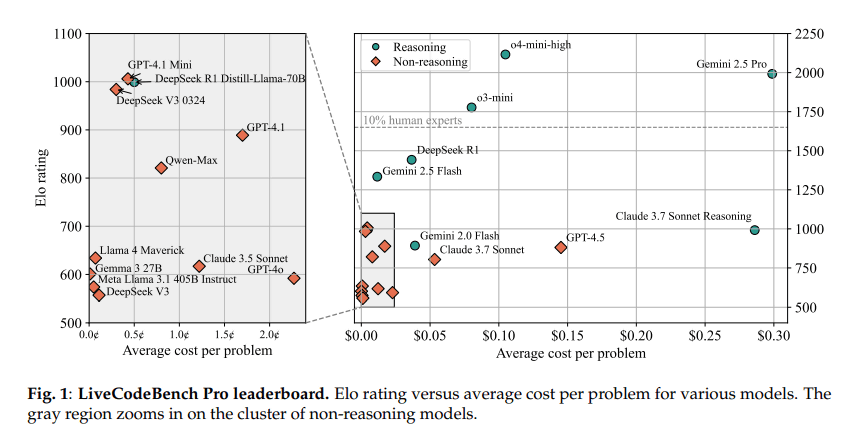
LLMは中難度の問題では53%の正答率を示しましたが、高難度の問題では正答率がゼロ%という結果が出ています。このことは、特に熟練したプログラマーが高難度の問題において優れた解決策を持っていることを示しています。実際に、OpenAIなどの最先端LLMですら、評価スコアは2100程度であり、優れたスキルを持つ人間は2700以上とされています。
LLMは実装に重きを置いた問題には強いものの、複雑なアルゴリズム推論には弱く、その結果、自信過剰な誤答を生成することも少なくありません。AIエンジニアのロハン・ポール氏は、「LLMのコーディング能力に関する非常に悪いニュース」とし、専門的な領域では人間のプログラマーが優位であることを強調しました。
この研究は、LLMの限界を理解し、今後の専門技術の向上に向けたヒントを提供することに寄与しています。
🧠 編集部より:
補足説明
この記事は、大規模言語モデル(LLM)が現実のプログラミングコンテストにおいて、いかに競技プログラマーに対して劣っているかを明らかにしたものです。また、LLMが特定のタイプの問題に対しては高い性能を発揮する一方で、アルゴリズムの推論や複雑な問題には依然として難しさがあると指摘しています。
LLMと競技プログラミング
LLMとは、膨大なデータを元にテキスト生成や自然言語処理を行うモデルのことで、最近ではコーディング支援にも利用されています。しかし、競技プログラミングのような難易度が高い問題では、依然として人間の専門家には歯が立たないという結果が報告されています。特に、危機的な状況での判断や、問題文のニュアンスを汲み取る能力には限界があります。
LiveCodeBench Pro
LiveCodeBench Proは、競技プログラミングの問題をもとに生成されたベンチマークで、Codeforces、ICPC(国際大学対抗プログラミングコンテスト)、IOI(国際情報オリンピック)の問題を含んでいます。このベンチマークを使用することで、LLMの性能を正確に測定し、どこでつまずくのかを特定することが可能になります。
スコアリングと結果
LLMのパフォーマンスは、イロレーティング方式で評価されますが、最高のモデルですら「約2100」のスコアでした。このスコアは、2700以上が優れたプログラマーとされるため、専門家との間には大きなひび割れがあります。現在のところ、LLMは実装精度に依存している部分が大きく、推論能力の向上にはさらなる研究が必要です。
豆知識
- 競技プログラミングでは、問題解決能力やアルゴリズムの知識だけでなく、タイムマネジメントやストレス耐性も重要です。
- LLMが生成するコードは、しばしば自信過剰で誤った選択をすることがあり、使用者はその点を注意しなければなりません。
関連リンク
技術の進化にもかかわらず、熟練した人間の技能がまだまだ必要とされていることを示すこの調査結果は、プログラミング教育の重要性を再認識させます。
-
キーワード: 競技プログラミング
※以下、出典元 ▶ 元記事を読む
Views: 0

{kind=link}