

はじめまして。menuのマイクロサービスチームに所属しているバックエンドエンジニアの石倉です。普段の業務ではGKEの運用やその上にデプロイされるアプリケーションのパフォーマンスチューニングとかSREっぽいことなどを行っています。
今回はGKE(Google Kubernetes Engine)にデプロイされるGoで書かれたワーカーが、スパイクするような高負荷なバッチを処理する時にCPUスロットリングが発生していたのでそれを回避した話の紹介と、簡単なデモを用いてkubernetesのCPU制限とGOMAXPROCSの最適な設定を体験してみようと思います。
単一のpodで稼働していたデータパイプラインワーカーのスループットが不足した
弊社menuではGoogle Cloudを主に利用しています。その中で、Cloud SQL for MySQLのデータ更新をトリガーにしてデータをCRMツールに連携するためのGoで書かれたワーカーがGKEに単一Podとしてデプロイされています。
こちらのデータパイプラインの処理は可能な限り早く処理を完了させたいという処理なのですが、深夜に実行されるバッチでDBに更新されるデータ量が増えてきて、こちらのワーカーのスループットが足りなくなったのでパフォーマンスを改善しました。
まず試したこと
まずPodにHPA(Horizontal Pod Autoscaler)が設定されておらず、高負荷時でもオートスケールしない状態だったのでHPAを設定しました。もともと単一Podで稼働していた理由は単一のPodでもスループットに問題がなかった点と、こちらのPodはCloud Pub/SubのPull型のサブスクライバー(サブスクリプションのタイプを選択する)として実行されており、Pull型のサブスクライバーを水平スケールした時に適切に負荷が分散されるのか?という点などが検証できていなかったため単一Podとして稼働させていました。
別のマイクロサービスでこちらのサブスクリプションの負荷分散の挙動は問題ないことが確認できていたためまずはHPAを導入することにしました。
オートスケールが鈍い
HPAを設定してオートスケールさせるようにして検証環境で商用環境と同じようなデータ量を処理させてみましたがオートスケールが鈍く思ったようにスループットは向上しませんでした。そのためアプリケーション側のボトルネックについて調査することにしました。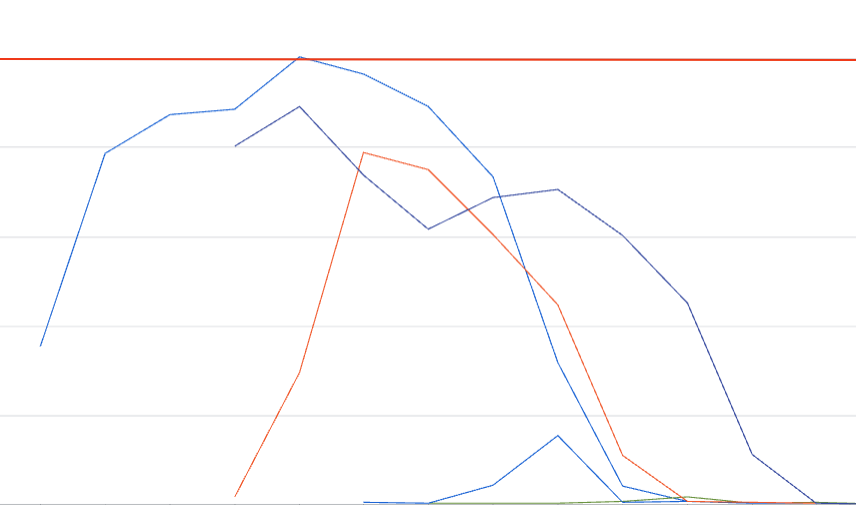
(赤い線がlimitsです)
CPUのlimitを超える瞬間がある
単一Podで高負荷時に処理しているときのCPU使用率をみると奇妙な現象に気がつきました。Kubernetesはコンピュータ資源を効率的に扱い運用を楽にするためOSSであり、そのPodがどれぐらいのリソースを扱うことができるのかを宣言することができます。しかし、対象Podの高負荷時このPodはリソース使用量が不安定で設定した条件を上回ることがありました。そういえばkubernetesでPod自身に与えられたCPUリソース量を超えるような処理を実行しようとした時の挙動について詳しくなかったので深ぼって調べることにしました。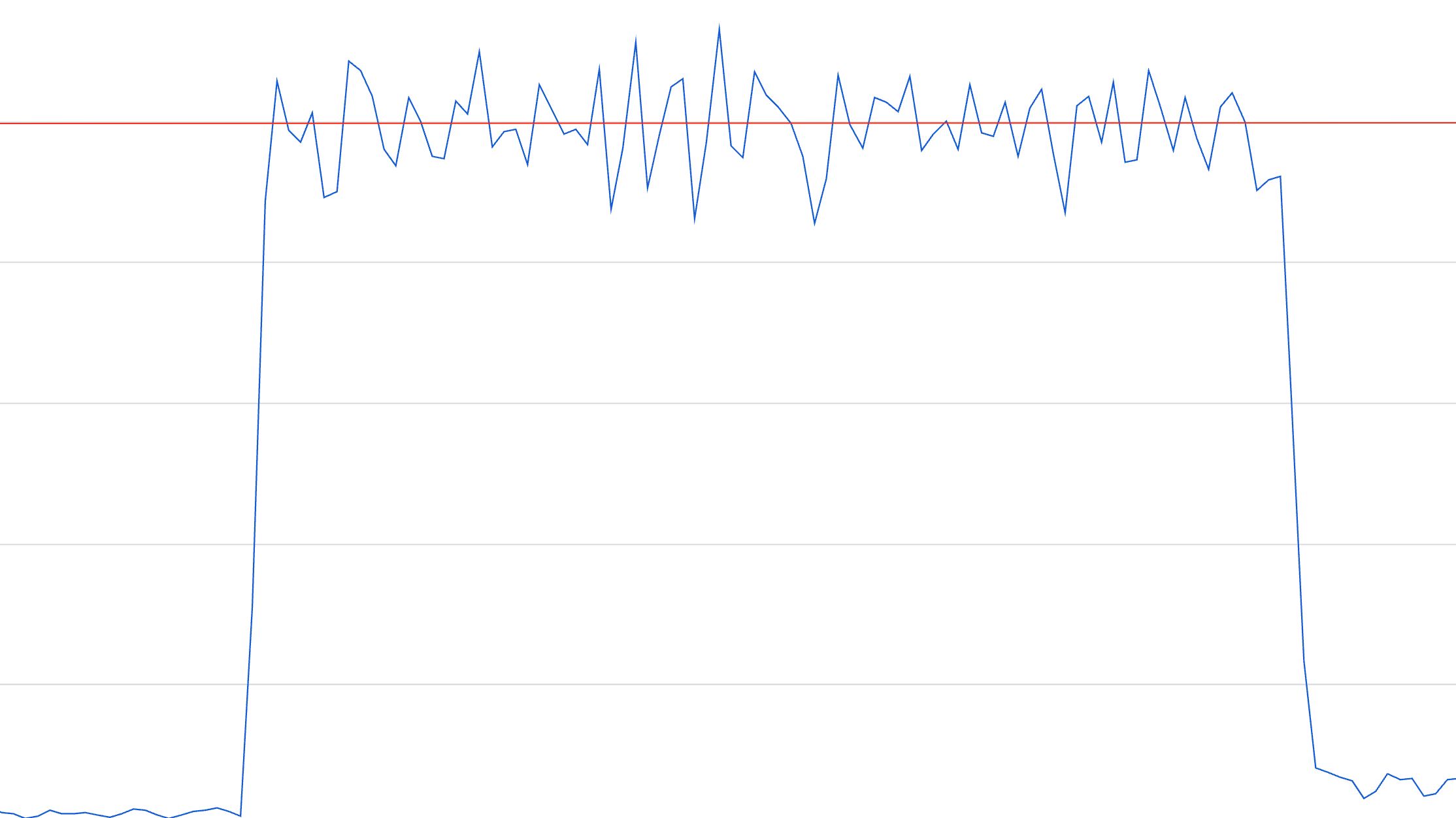
CPUスロットリング
CPUスロットリングとは、プロセスが与えられたリソース量に到達しそうになったとき、そのプロセスを減速させる動作のことです。この仕組みがあることによってたくさんのサービスを同じノード上で運用することになってもリソースの過剰利用を防止することができ、ノード全体の安全性を守ることができます。
kubernetesの場合以下のようにマニフェストのlimitsで指定した部分を超えた値を使用した時に発生します。
ノード上のリソースが余っていたとしてもスロットリングされます。
resources:
requests:
cpu: 500m
limits:
cpu: 1000m
また余談ですが弊社はGKEのAutopilotモードというのを利用しています。こちらはノードのマネージドで管理してくれる設定です。GKE Autopilotのバースト機能をサポートしていないクラスタはrequestsとlimitsを異なる値で設定できないようです。(Autopilot でのリソース リクエスト)
GoのGOMAXPROCSを過剰に設定することによるCPUスロットリングによるパフォーマンス低下
GOMAXPROCSとはユーザーレベルのGoコードを同時に実行できるOSスレッドの最大数です。https://pkg.go.dev/runtime
つまり実際に同時に実行できるgoroutineの最大数を決定する環境変数です。今回パフォーマンス改善をする対象のプログラムはGo1.21を使用しており、デフォルト値はホストOSの論理CPU数を返すように設定されているようです。
そんなGOMAXPROCSという環境変数ですが、実際のCPUクォータよりも大幅に高い値を設定してしまうと、Goアプリケーションはより多くのOSスレッドを起動しようとしてしまい、与えられたCPUクォータを早期に消費してしまいCPUスロットリングが発生し、性能が低下するようです。
特にkubernetesではGo1.21の場合GOMAXPROCSがノードのコア数になってしまうため、それよりも少ないCPUリソースを割り当てられていた場合、コア数のミスマッチが起こってしまい大幅なパフォーマンス低下が発生します。
automaxprocsを導入した
importするだけでLinuxコンテナのCPUクォータに合わせて自動的にGOMAXPROCSを設定してくれるautomaxprocsというライブラリを導入しました。
こちらのREADMEにも記載されている通り、あたえられたCPUクォータと同じ値にするといちばんパフォーマンスが良さそうです。
また、Go1.25ではautomaxprocsを導入しなくても動的に利用可能なリソースに基づいて自動的に調整されるようになるようです。Go 1.25 Release Notes
サブスクライバーのMaxOutstandingMessagesを絞る
Cloud Pub/SubのサブスクライバーのクライアントにはMaxOutStandingMessagesという環境変数が用意されています。これは「クライアントが受信し、アプリケーションのコールバックで ACK/NACK を返すまでメモリ上に保持する最大メッセージ数」
を示します。今回は水平スケールを導入してよりそれぞれのPodに分散して処理して欲しかったのでこちらの環境変数を小さめの値を設定するようにしました。(もちろん設定した値で負荷検証を行いました)
綺麗にスケールするようになった
GOMAXPROCSとMaxOutstandingMessagesを調整すると綺麗にスケールするようになりました。CPUスロットリングを回避した影響がかなり大きかったようで、1Pod時のスループットがかなり向上しました。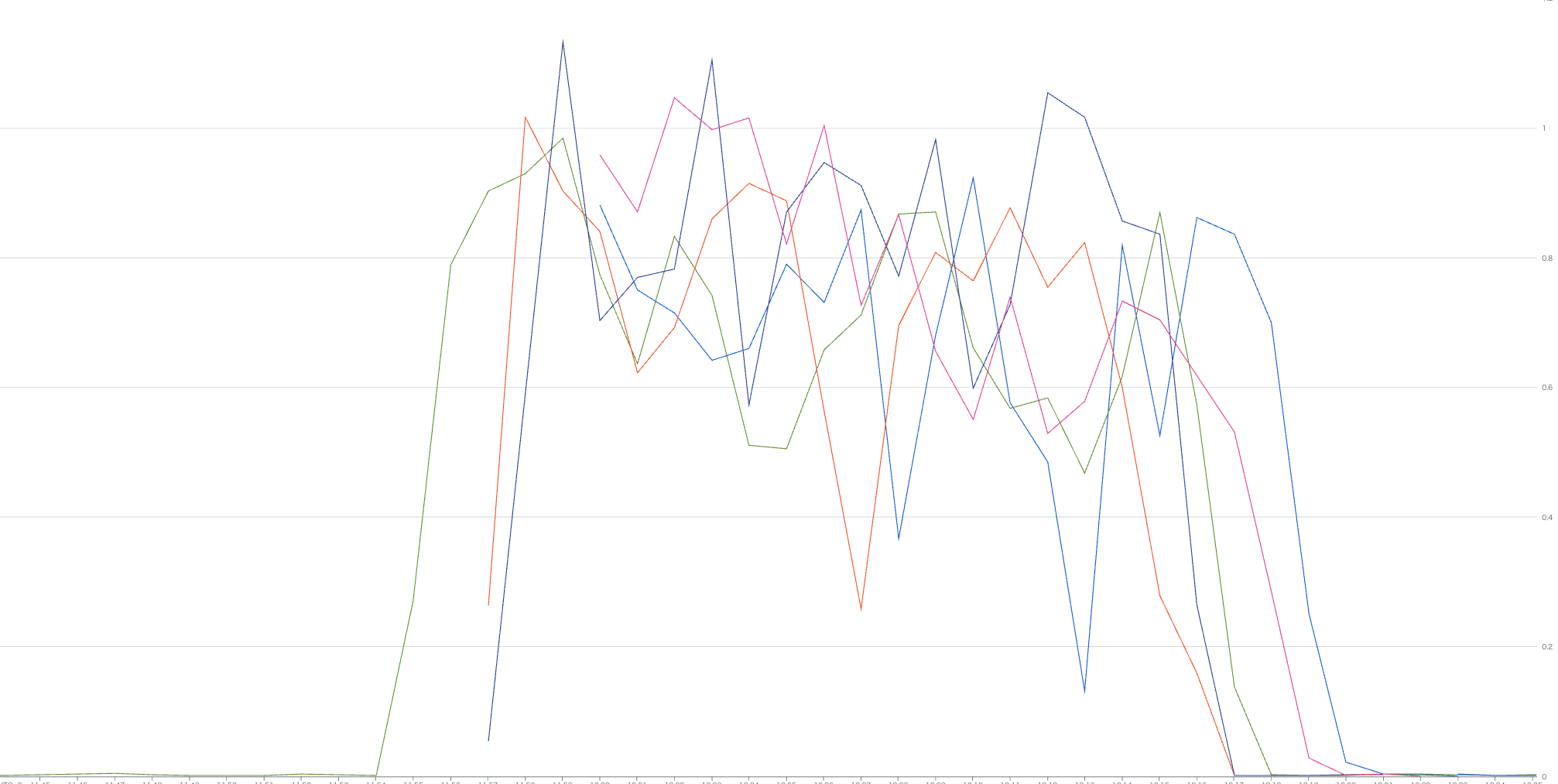
簡易的なデモを使ってCPUスロットリングを体験してみる
cursorに作ってもらって、自分で少し修正したデモがこちらです。(レビューしきれてない部分もあるのでご了承ください。)
minikubeを用いCPU100mを割り当てた簡単なhttpサーバーのPodをローカルに立ててCPUバウンドな処理をさせて、GOMAXPROCSを変えてみてレスポンスタイムを比べます。
メトリクスはPrometheusで取得してGrafanaで可視化してます。負荷はk6をつかってかけています。
検証用のPodへ与えるリソースは全て以下
resources:
requests:
memory: "64Mi"
cpu: "100m"
limits:
memory: "128Mi"
cpu: "100m"
検証用のPodは全て5つ(6つ目もlimitsを設定してないパターンも用意してますが今回は使ってません。)
それぞれ以下のように設定しています。
| デプロイメント | GOMAXPROCS 設定 |
|---|---|
| cpu-demo-maxprocs-0 | デフォルト (6) |
| cpu-demo-maxprocs-1 | 1 |
| cpu-demo-maxprocs-2 | 2 |
| cpu-demo-maxprocs-3 | 3 |
| cpu-demo-maxprocs-8 | 8 |
| CPUリミットが1vCPU(1000m)以下ならGOMAXPROCSは1が適切なので、今回は100m割り当てるので期待値としてはcpu-demo-maxprocs-1が一番パフォーマンスが良いことです。 | |
| 環境を準備したらrun-load-test.shを実行してそれぞれの環境へ負荷をかけていきます。 | |
run-load-test.shの中のITERATIONSとPARALLELISMを変更することでloopの回数とgoroutineの生成数を調整できます。 |
|
| 今回はITERATIONS=10000000,PARALLELISM=8としました。 | |
| k6で指定できる仮想ユーザー数は2にしてます。この数は同時並行で実行される擬似的なユーザー数です。仮想ユーザーはレスポンスが帰ってきたらすぐ次のリクエストを投げるような簡単なシナリオになっています。 |
デモの結果
まずCPU使用率はそれぞれ与えられた上限の100mに達しました。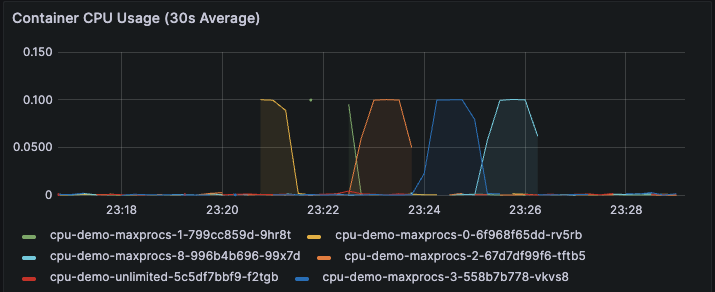
RPSは期待値通りcpu-demo-maxprocs-1が一番良さそうです。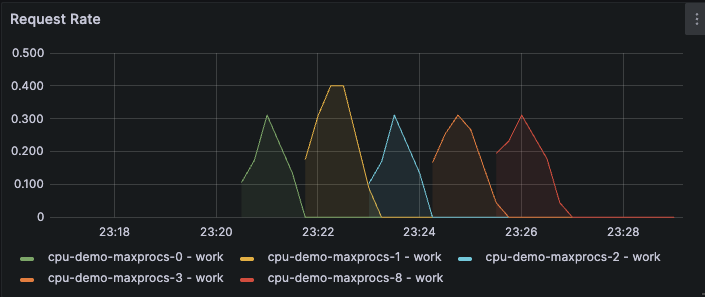
レスポンスタイムも期待値通りcpu-demo-maxprocs-1がパフォーマンスが良さそうです。(パネルのタイトルが95percentileとなってますが途中でいじったので50percentileです。わかりずらくてすみません。)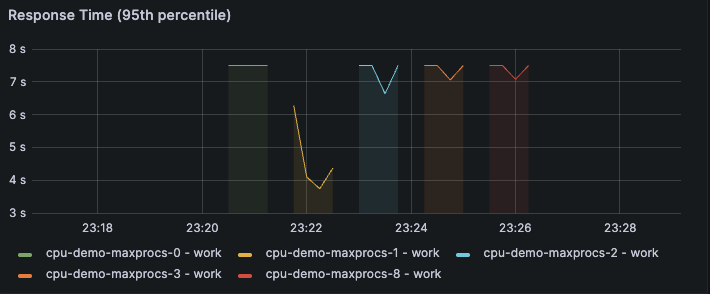
CPU Thorottling Ratioも取得できたので表示してみました。どれぐらい性格なメトリクスなのかわかりませんが、GOMAXPROCSが6(cpu-demo-maxprocs-0)や8(cpu-demo-maxprocs-8)など過剰な値を設定したもに関しては75%を超えておりかなり抑制されてそうです。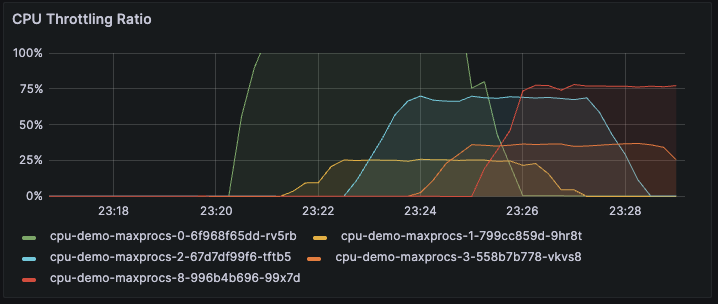
まとめ
今回はGoのGOMAXPROCSを適切に設定しk8s環境でCPUスロットリングを解消してパフォーマンスを向上させた話を紹介しました。
Go1.25移行はデフォルト値が動的に変わってくれそうなのであまり意識しなくてよくなりそうですね。
▼採用情報
レアゾン・ホールディングスは、「世界一の企業へ」というビジョンを掲げ、「新しい”当たり前”を作り続ける」というミッションを推進しています。
現在、エンジニア採用を積極的に行っておりますので、ご興味をお持ちいただけましたら、ぜひ下記リンクからご応募ください。
Views: 0

{kind=link}